前言
最近在和朋友写一个二手房的项目,需要用到爬虫,这里借助了scrapy来写。顺便整理了scrapy的用法.
fous_seas/sources
第一个 Spider
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
|
可以看到,我们新建的 QuotesSpider 类是继承自 scrapy.Spider 类的;下面看看其属性和方法的意义.
是 Spider 的标识符,用于唯一标识该 Spider;它必须在整个项目中是全局唯一的.
必须定义并返回一组可以被 Spider 爬取的 Requests,Request 对象由一个 URL 和一个回调函数构成.
就是 Request 对象中的回调方法,用来解析每一个 Request 之后的 Response;所以,parse() 方法就是用来解析返回的内容,通过解析得到的 URL 同样可以创建对应的 Requests 进而继续爬取.
再来看看具体的实现。
方法分别针对 http://quotes.toscrape.com/page/1/ 和 http://quotes.toscrape.com/page/2/ 创建了两个需要被爬取的 Requests 对象;并通过 yield 进行迭代返回;备注,yield 是迭代生成器,是一个 Generator;
对 Request 的反馈的内容 Response 进行解析,这里的解析的逻辑很简单,就是分别创建两个本地文件,然后将 response.body 的内容放入这两个文件当中。
大致会输出如下内容
1
2
3
4
5
6
7
8
9
10
11
| ...
2016-12-16 21:24:05 [scrapy.core.engine] INFO: Spider opened
2016-12-16 21:24:05 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-12-16 21:24:05 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2016-12-16 21:24:05 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2016-12-16 21:24:05 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
2016-12-16 21:24:05 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/2/> (referer: None)
2016-12-16 21:24:05 [quotes] DEBUG: Saved file quotes-1.html
2016-12-16 21:24:05 [quotes] DEBUG: Saved file quotes-2.html
2016-12-16 21:24:05 [scrapy.core.engine] INFO: Closing spider (finished)
...
|
可以看到,通过爬取,我们在本地生成了两个 html 文件 quotes-1.html 和 quotes-2.html
如何提取
通过命令行的方式提取
Scrapy 提供了命令行的方式可以对需要被爬取的内容进行高效的调试,通过使用Scrapy shell进入命令行,然后在命令行中可以快速的对要爬取的内容进行提取;
一定要学会调试!!!这是不能跳过的步骤
我们试着通过 Scrapy shell 来提取下 “http://quotes.toscrape.com/page/1/" 中的数据,通过执行如下命令,进入 shell
1
2
3
4
5
6
| scrapy shell "http://quotes.toscrape.com/page/1/"
// 或者
scrapy shll
fetch('http://quotes.toscrape.com/page/1/')
|
输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [ ... Scrapy log here ... ]
2016-09-19 12:09:27 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7fa91d888c90>
[s] item {}
[s] request <GET http://quotes.toscrape.com/page/1/>
[s] response <200 http://quotes.toscrape.com/page/1/>
[s] settings <scrapy.settings.Settings object at 0x7fa91d888c10>
[s] spider <DefaultSpider 'default' at 0x7fa91c8af990>
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
>>>
|
这样,我们就进入了 Scrapy shell 的环境,上面显示了连接请求和返回的相关信息,response 返回 status code 200 表示成功返回;
通过 CSS 标准进行提取
这里主要是遵循 CSS 标准 https://www.w3.org/TR/selectors/ 来对网页的元素进行提取.
通过使用 css() 选择我们要提取的元素
下面演示一下如何提取元素.
1
2
| >>> response.css('title')
[<Selector xpath=u'descendant-or-self::title' data=u'<title>Quotes to Scrape</title>'>]
|
可以看到,它通过返回一个类似 SelectorList 的对象成功的获取到了 http://quotes.toscrape.com/page/1/ 页面中的
的信息,该信息是封装在Selector对象中的 data 属性中的.
提取Selector元素的文本内容,一般有两种方式用来提取
- 通过使用 extract() 或者 extract_first() 方法来提取元素的内容;下面演示如何提取 #1 返回的元素 中的文本内容 text;
1
2
| >>> response.css('title::text').extract_first()
'Quotes to Scrape'
|
- extract_first() 表示提取返回队列中的第一个 Selector 对象;同样也可以使用如下的方式.
1
2
| >>> response.css('title::text')[0].extract()
'Quotes to Scrape'
|
不过 extract_first() 方法可以在当页面没有找到的情况下,避免出现IndexError的错误;
- 通过 re() 方法来使用正则表达式的方式来进行提取元素的文本内容
1
2
3
4
5
6
| >>> response.css('title::text').re(r'Quotes.*')
['Quotes to Scrape']
>>> response.css('title::text').re(r'Q\w+')
['Quotes']
>>> response.css('title::text').re(r'(\w+) to (\w+)')
['Quotes', 'Scrape']
|
使用 XPath
除了使用 CSS 标准 来提取元素意外,我们还可以使用 XPath 标准来提取元素,比如:
1
2
3
4
| >>> response.xpath('//title')
[<Selector xpath='//title' data='<title>Quotes to Scrape</title>'>]
>>> response.xpath('//title/text()').extract_first()
'Quotes to Scrape'
|
XPath 比 CSS 的爬取方式更为强大,因为它不仅仅是根据 HTML 的结构元素去进行检索(Navigating),并且它可以顺带的对文本(text)进行检索;所以它可以支持 CSS 标准不能做到的场景,比如,检索一个 包含文本内容”Next Page”的 link 元素;这就使得通过 XPath 去构建爬虫更为简单.
数据流设计图
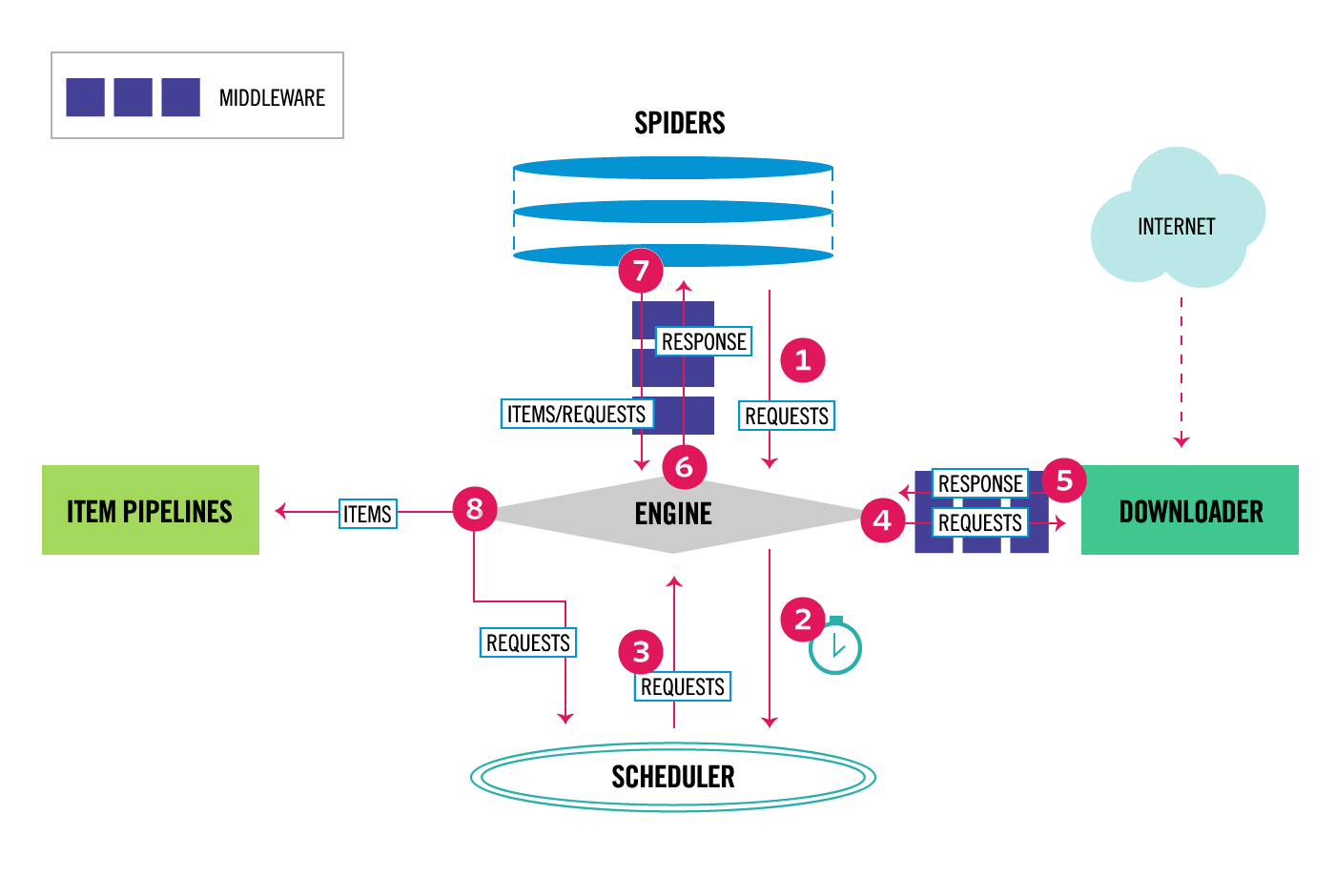
Items
Scrapy 的核心目的就是从非结构化的网页中提取出结构化的数据;默认的,Scrapy 爬虫以 dicts 的形式返回格式化的数据;但是,这里有一个问题,就是 dicts 并不能很好的表示这种结构化数据的结构,而且经常容易出错,转换也麻烦。
因此,Item 诞生了,它提供了这样一个简单的容器来收集爬取到的数据,并提供非常简便的 API 来声明它的 fields。
声明 Items
通过一个简单的 class 和多个 Field 对象来声明 Items 对象;看一个 Product Item 的例子。
1
2
3
4
5
6
7
| import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
|
需要注意的是,Product 继承自 scrapy.Item 父类.