前言 CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
msource 是我们的一个 数据源组件,我们所有的大数据ETL服务都构建在此之上,所以我们msource可以说是所有业务系统的核心。他维护着一个稳定,可靠,高性能的数据传输机制。让我们 业务层 中可以做各种操作,同步,异步等等。
msource 的角色我大体分为了2种:
spout (数据推送组件)
db (数据存储组件)
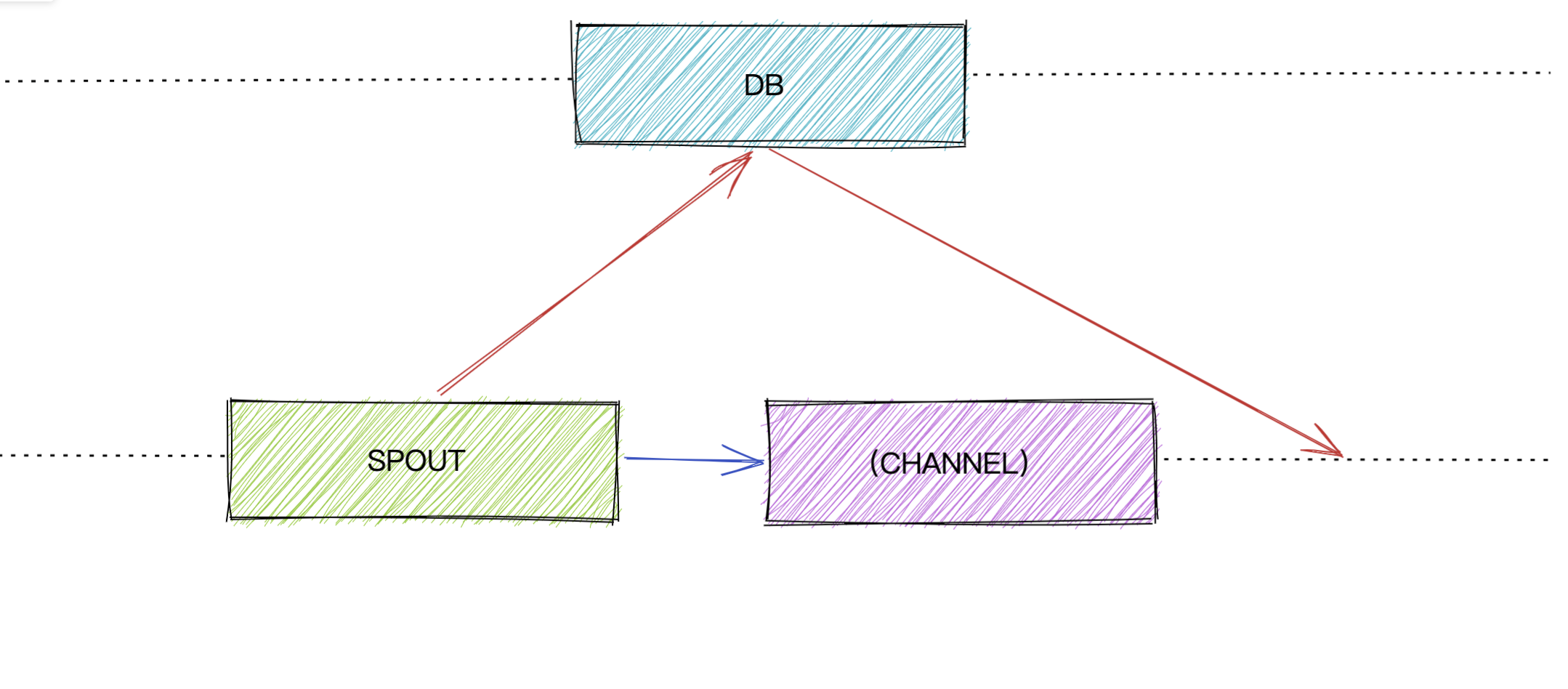
在这个图中,我们可以看到,db可以独立出来应用,他不依赖于spout。spout默认的传输机制是我们golang中的channel模式,但是它可以选择使用db模式。
MSOURCE_DB RockesDB的基础知识 rocksdb 我们知道他是支持WAL(Write Ahead Log)的,一般的log文件中通常包括 redo log 和 undo log。其实这不仅仅是rocksdb独有的,这是一种可靠性的保证,像mysql一样有这种机制,也是分为redo log, undo log, binlog,区别就在于 binlog 属于逻辑日志,redo log和undo log属于物理日志。
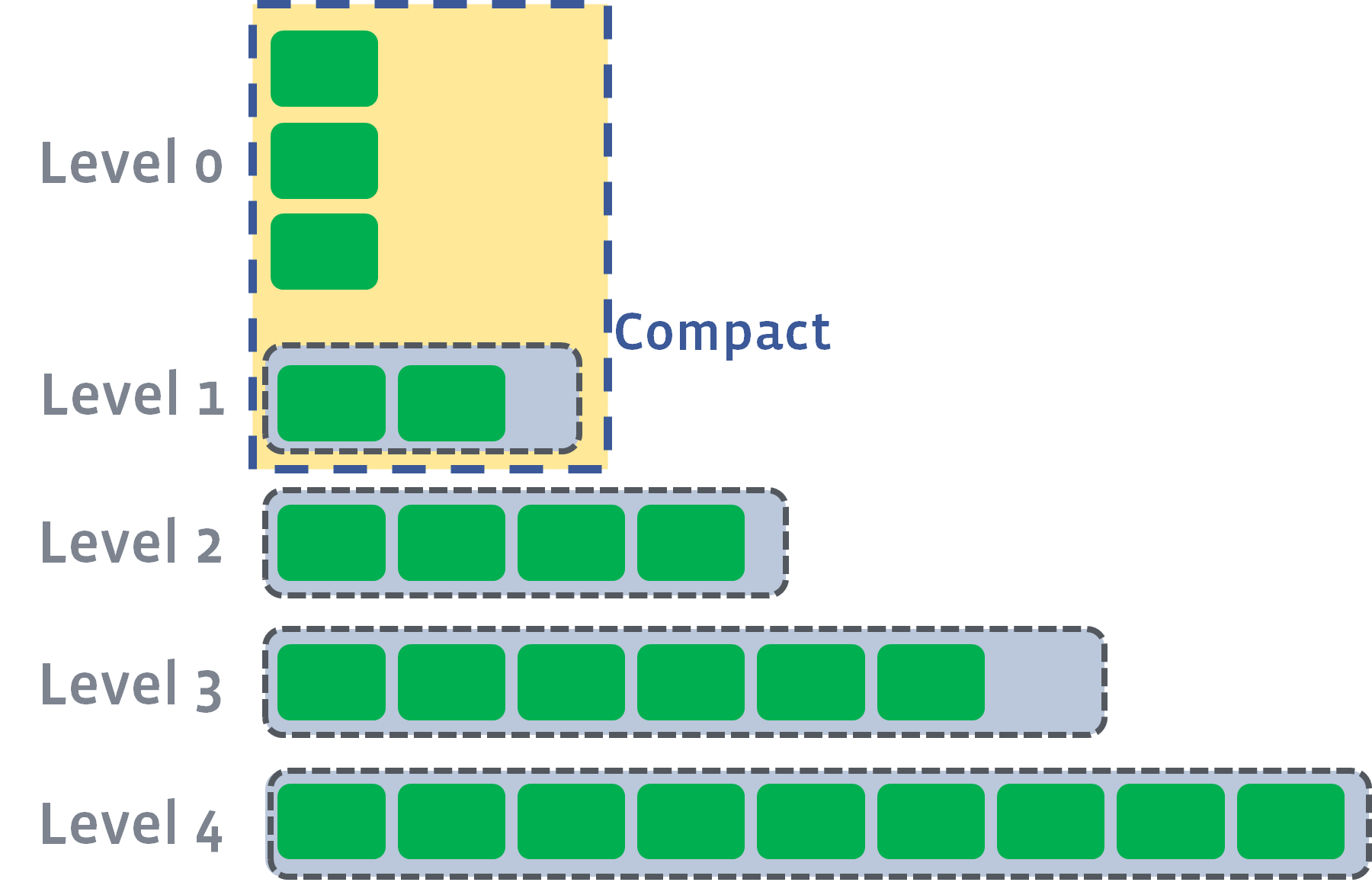
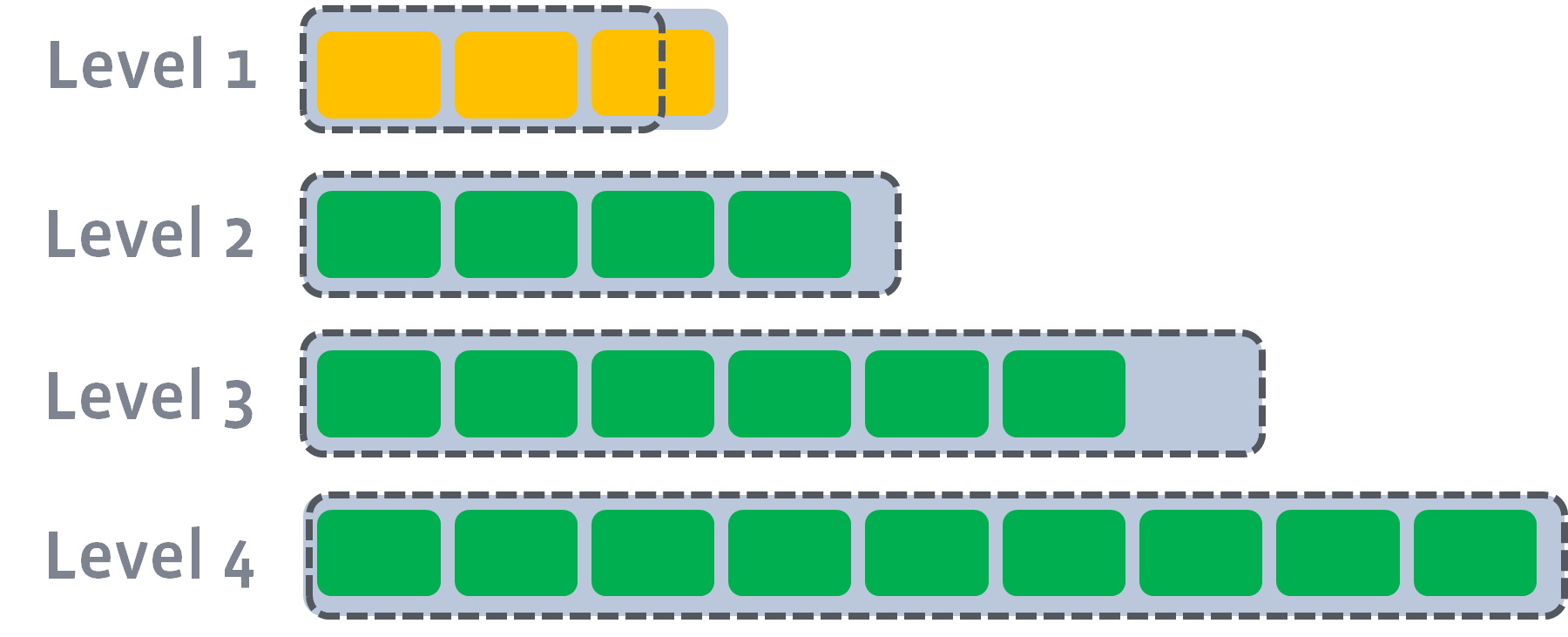
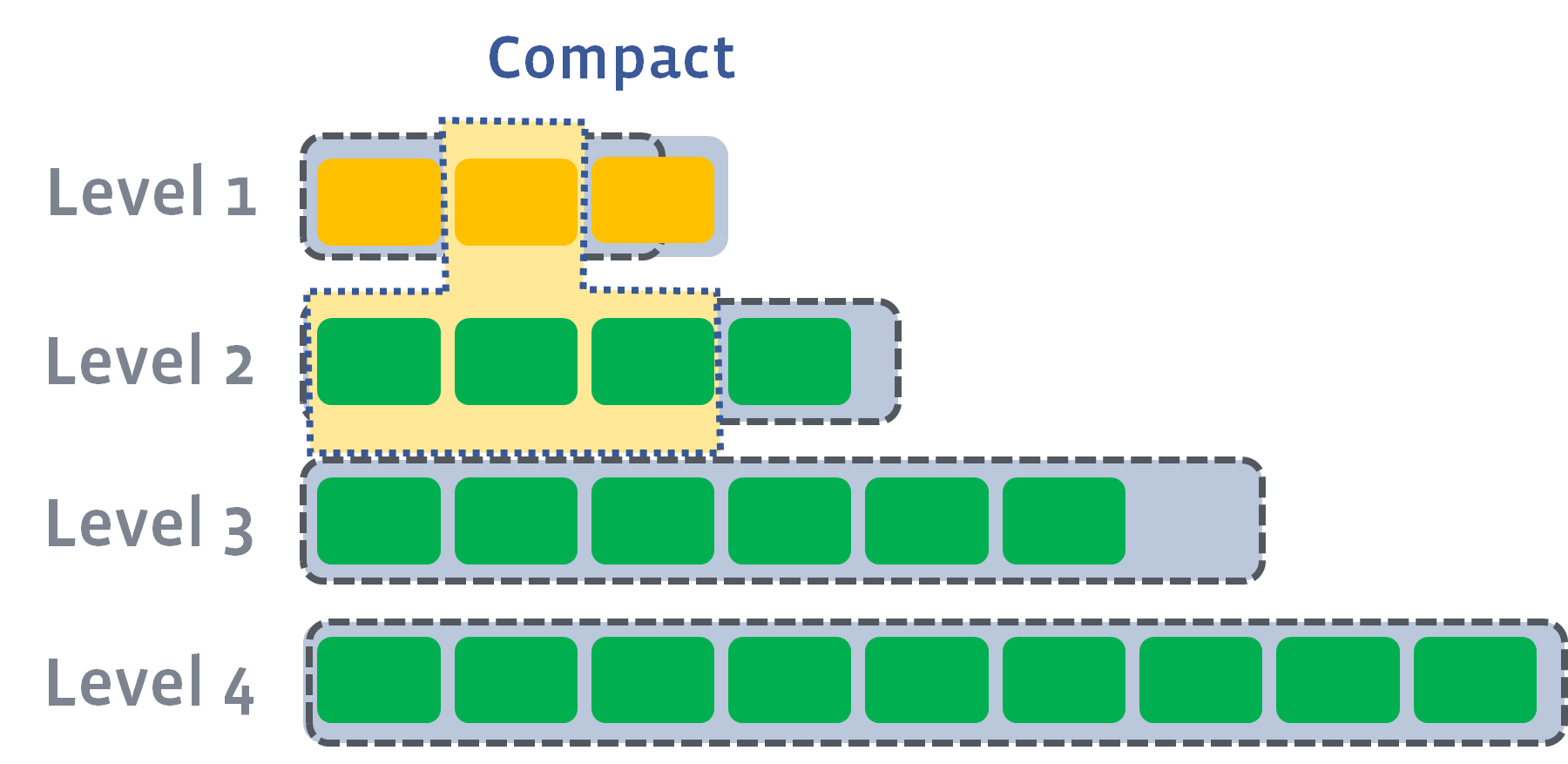
rocksdb是facebook开发的一个kv存储引擎。他的机构模式是基于LSM的。基于LSM的架构都需要经过一个叫 Compaction 过程,通常Compaction涉及到三个放大因子。
Compaction需要在三者之间做取舍。
写放大 (Write Amplification)
读放大(Read Amplification)
空间放大 (Space Amplification)
后台的 compaction 来减少读放大(减少 SST 文件数量)和空间放大(清理过期数据),但也因此带来了写放大(Write Amplification)的问题。
Compaction 写放大 假设每秒写入10MB的数据,但观察到硬盘的写入是30MB/s,那么写放大就是3。写分为立即写和延迟写,比如redo log是立即写,传统基于B-Tree数据库刷脏页和LSM Compaction是延迟写。redo log使用direct IO写时至少以512字节对齐,假如log记录为100字节,磁盘需要写入512字节,写放大为5。
DirectIO是直接操作IO,不经过BufferIO。
读放大 对应于一个简单query需要读取硬盘的次数。比如一个简单query读取了5个页面,发生了5次IO,那么读放大就是 5。假如B-Tree的非叶子节点都缓存在内存中,point read-amp 为1,一次磁盘读取就可以获取到Leaf Block;short range read-amp 为12,12次磁盘读取可以获取到所需的Leaf Block。
操作需要从新到旧(从上到下)一层一层查找,直到找到想要的数据。这个过程可能需要不止一次 I/O。特别是 range query 的情况,影响很明显。
空间放大 假设我需要存储10MB数据,但实际硬盘占用了30MB,那么空间放大就是3。有比较多的因素会影响空间放大,比如在Compaction过程中需要临时存储空间,空间碎片,Block中有效数据的比例小,旧版本数据未及时删除等等。
所有的写入都是顺序写 append-only 的,不是 in-place update,所以过期数据不会马上被清理掉。
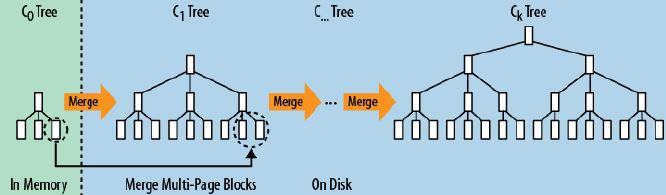
LSM 树 LSM 树的设计思想非常朴素, 它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。磁盘中的树定期可以做 merge 操作,合并成一棵大树,以优化读性能【读数据的过程可能需要从内存 memtable 到磁盘 sstfile 读取多次,称之为读放大】。RocksDB 的 LSM 体现在多 level 文件格式上,最热最新的数据尽在 L0 层,数据在内存中,最冷最老的数据尽在 LN 层,数据在磁盘或者固态盘上。
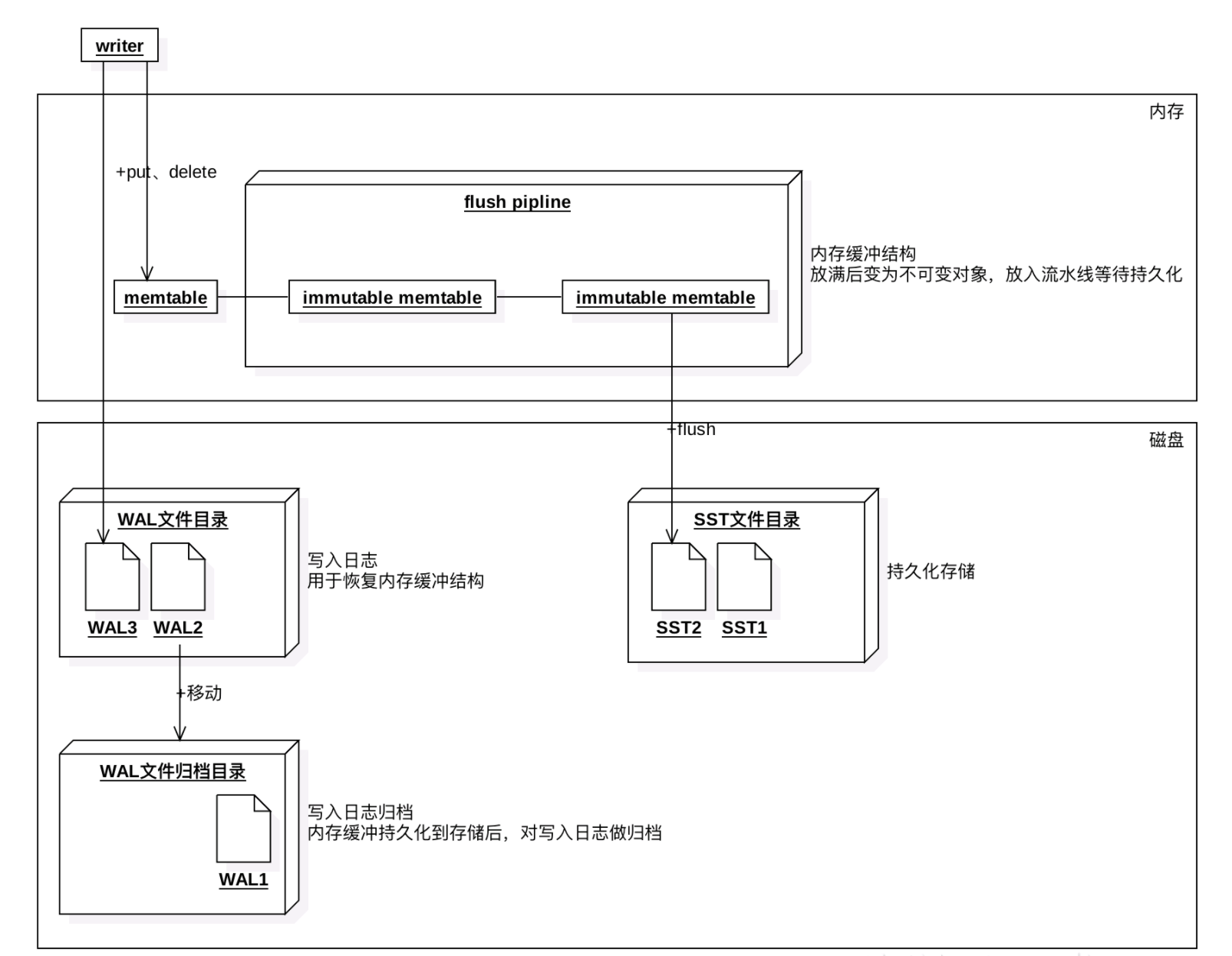
Rocksdb RocksDB的三种基本文件格式是 memtable / sstfile / logfile,memtable 是一种内存文件数据系统,新写数据会被写进 memtable,部分请求内容会被写进 logfile。logfile 是一种有利于顺序写的文件系统。memtable 的内存空间被填满之后,会有一部分老数据被转移到 sstfile 里面,这些数据对应的 logfile 里的 log 就会被安全删除
单独的 Get/Put/Delete 是原子操作,要么成功要么失败,不存在中间状态。
如果需要进行批量的 Get/Put/Delete 操作且需要操作保持原子属性,则可以使用 WriteBatch。
L0 -> L1
L1 -> L2
L1 -> L2
可以看到主要的三个组成部分,内存结构memtable,类似事务日志角色的WAL文件,持久化的SST文件。
数据会放到内存结构memtable,当memtable的数据大小超过阈值(write_buffer_size)后,会新生成一个memtable继续写,将前一个memtable保存为只读memtable。当只读memtable的数量超过阈值后,会将所有的只读memtable合并并flush到磁盘生成一个SST文件。
这里的SST属于level0, level0中的每个SST有序,可能会有交叉。写入WAL文件是可选的,用来恢复未写入到磁盘的memtable。
memtable如其名为一种内存的数据结构。通过设置memtable的大小、总大小来控制何时flush到SST文件。大部分格式的memtable不支持并发写入,并发调用依然会依次写入。目前仅支持skiplist。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 rocksdb: options: create.if.missing: true error.if.exists: false paranoid.checks: false info.log.level: 3 increase.parallelism: 4 allow.concurrent.memtable.writes: false write.buffer.size: 64 * 1024 * 1024 max.write.buffer.number: 4 min.write.buffer.number.to.merge: 1 max.open.files: 1000 max.file.opening.threads: 16 compression: 1 num.levels: 7 level0.file.num.compaction.trigger: 4 level0.slowdown.writes.trigger: 8 level0.stop.writes.trigger: 12 max.mem.compaction.level: 2 target.file.size.base: &target_file_size_base 2 * 1024 * 1024 target.file.size.multiplier: 1 max.bytes.for.level.base: 10 * 1024 * 1024 max.bytes.for.level.multiplier: 10.0 level.compaction.dynamic.level.bytes: false max.compaction.bytes: *target_file_size_base * 25 soft.pending.compaction.bytes.limit: 64 * 1024 * 1024 * 1024 hard.pending.compaction.bytes.limit: 256 * 1024 * 1024 * 1024 use.fsync: false db.log.dir: "" wal.dir: "" delete.obsolete.files.period.micros: 6 * 60 * 60 * 1000 * 1000 max.background.compactions: 2 max.background.flushes: 0 max.log.file.size: 0 log.file.time.to.roll: 24 * 60 * 60 keep.log.file.num: 30 soft.rate.limit: 0.0 hard.rate.limit: 0.0 rate.limit.delay.max.milliseconds: 1000 max.manifest.file.size: 1 <<64 - 1 table.cache.numshardbits: 4 table.cache.remove.scan.count.limit: 16 arena.block.size: 0 disable.auto.compactions: false w.a.l.recovery.mode: 0 w.a.l.ttl.seconds: 0 wal.size.limit.mb: 0 enable.pipelined.write: false manifest.preallocation.size: 1024 * 1024 * 4 purge.redundant.kvs.while.flush: true allow.mmap.reads: false allow.mmap.writes: false use.direct.reads: false use.direct.i.o.for.flush.and.compaction: false is.fd.close.on.exec: true skip.log.error.on.recovery: false stats.dump.period.sec: 3600 advise.random.on.open: true db.write.buffer.size: 0 access.hint.on.compaction.start: 1 use.adaptive.mutex: false bytes.per.sync: 0 compaction.style: 0 max.sequential.skip.in.iterations: 8 inplace.update.support: false inplace.update.num.locks: 0 memtable.huge.page.size: 0 bloom.locality: 0 max.successive.merges: 0 enable.statistics: false prepare.for.bulk.load: false memtable.vector.rep: false create.if.missing.column.families: true
SQL-AST的支持 我们的db希望能做到与语言无关,不仅仅是我们的目前的golang,就算是php也可以用到本地持久化的方式的话,就需要借助RPC协议或者特定DSL来实现,但是既然是数据库,这里优先选择了以sql语法来管理数据。
那么我们就需要拿到sql的抽象语法树(sql-ast),拿到sql-ast之后,我们就可以拿到我们所需要的信息去hit data。
Pingcap-parser
这里我们用到了pingcap公司的parser库,该库同样是TiDB的sql解析库,借助该库,我们可以很方便的拿到sql-ast
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 package mainimport ( "fmt" "github.com/pingcap/parser" _ "github.com/pingcap/parser/test_driver" ) type visitor struct { table string fields []string } func (v *visitor) Enter (in ast.Node) (out ast.Node, skipChildren bool ) switch n := in.(type ) { case *ast.SelectStmt: case *ast.FieldList: case *ast.SelectField: case *ast.ColumnNameExpr: case *ast.ColumnName: case *ast.TableName: case *ast.BinaryOperationExpr: case *ast.Join: } return in, false } func (v *visitor) Leave (in ast.Node) (out ast.Node, ok bool ) fmt.Printf("Leave: %T\n" , in) switch n := in.(type ) { case *ast.SelectStmt: case *ast.FieldList: case *ast.SelectField: case *ast.ColumnNameExpr: case *ast.ColumnName: case *ast.TableName: v.table = n.Name.L case *ast.BinaryOperationExpr: } return in, true } func main () p := parser.New() sql := "SELECT emp_no, first_name, last_name " + "FROM employees " + "where id='Aamodt' and (create_time > 0 or last_name ='caiwenhui')" stmtNodes, _, err := p.Parse(sql, "" , "" ) if err != nil { fmt.Printf("parse error:\n%v\n%s" , err, sql) return } for _, stmtNode := range stmtNodes { v := visitor{} stmtNode.Accept(&v) fmt.Printf("%v\n" , v) } }
这里用到了github.com/pingcap/parser/test_driver 的原因是因为该库和tidb的driver存在依赖关系,tidb在设计的时候,并未做到很好的分离,所以当其他项目需要使用该库的时候,需要引入这个驱动。
1 2 3 4 5 6 7 8 9 10 11 12 13 type Visitor interface { Enter(n Node) (node Node, skipChildren bool ) Leave(n Node) (node Node, ok bool ) }
并且这里,我们看到有一个结构体visitor,该结构体就是用来访问ast用的,因为 tidb的parser库 和阿里巴巴 的 druid sql 类似,都是采用 访问器的方式来遍历 ast的,所以我们只需要定义好我们的访问器,那么就可以访问对应的结构数据。Enter(n Node) (node Node, skipChildren bool),另外一个是 Leave(n Node) (node Node, ok bool) 。2个接口返回的第二个参数分别定义为 是否跳过剩下的节点, 是否成功退出节点。
interface在这里的应用 在parser中,大量运用了interface, 充分的给我们的展示了golang的组合特性。
例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 type Node interface { Restore(ctx *format.RestoreCtx) error Accept(v Visitor) (node Node, ok bool ) Text() string SetText(text string ) } type SelectStmt struct { dmlNode resultSetNode *SelectStmtOpts Distinct bool From *TableRefsClause Where ExprNode Fields *FieldList GroupBy *GroupByClause Having *HavingClause WindowSpecs []WindowSpec OrderBy *OrderByClause Limit *Limit LockTp SelectLockType TableHints []*TableOptimizerHint IsAfterUnionDistinct bool IsInBraces bool QueryBlockOffset int SelectIntoOpt *SelectIntoOption } func splitWhere (where ast.ExprNode) []ast .ExprNode var conditions []ast.ExprNode switch x := where.(type ) { case nil : case *ast.BinaryOperationExpr: if x.Op == opcode.LogicAnd { conditions = append (conditions, splitWhere(x.L)...) conditions = append (conditions, splitWhere(x.R)...) } else { conditions = append (conditions, x) } case *ast.ParenthesesExpr: conditions = append (conditions, splitWhere(x.Expr)...) default : conditions = append (conditions, where) } return conditions }
ast.Node 是ast的基础接口,所有的节点都需要在此之上实现自己的功能。其他接口同理,一环扣一环,设计得十分巧妙。
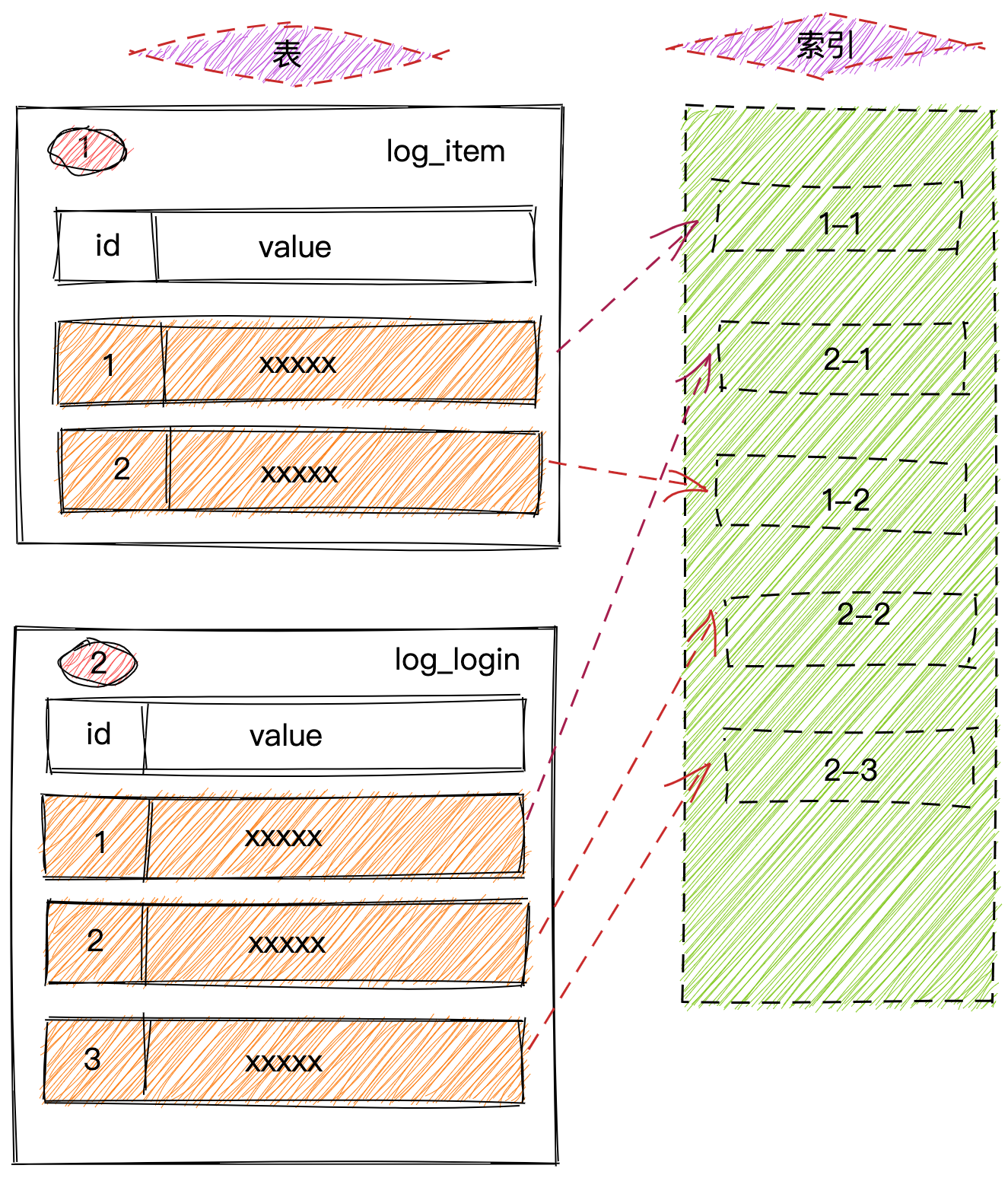
KEY-VALUE的编码规则 DB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID, 其中 DbId/TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
其中细节如下:
database 编码成 Key-Value pair:
1 2 Key: metaPrefix(+)databasePrefix{dbID} Value: database struct json marshal
database indexed 编码成 Key-Value pair:
1 2 Key: metaPrefix(+)databasePrefix_indexPrefix{database_name} Value: dbID
table 编码成 Key-Value pair:
1 2 Key: metaPrefix(+)tablePrefix{dbID}_recordPrefixSep{tableID} Value: table struct json marshal
table indexed 编码成 Key-Value pair:
1 2 Key: metaPrefix(+)tablePrefix{dbID}_indexPrefix{databaseId}{table_name} Value: tableID
每行数据按照如下规则进行编码成 Key-Value pair:
1 2 Key: databasePrefix{dbID}_tablePrefix{tableID}_recordPrefixSep{rowID} Value: [col1, col2, col3, col4]
对于 Unique Index 数据,会按照如下规则编码成 Key-Value pair:
1 2 Key: databasePrefix{dbID}_tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue Value: rowID
Index 数据还需要考虑 Unique Index 和非 Unique Index 两种情况,对于 Unique Index,可以按照上述编码规则。 但是对于非 Unique Index,通过这种编码并不能构造出唯一的 Key,因为同一个databasePrefix{dbID}_tablePrefix{tableID}_indexPrefixSep{indexID}都一样,可能有多行数据的 ColumnsValue 是一样的.
对于 “非” Unique Index 的编码做了一点调整:
1 2 Key: databasePrefix{dbID}_tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_{rowID} Value: null
对应的标识符如下定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 var ( databasePrefix = []byte {'d' } tablePrefix = []byte {'t' } recordPrefixSep = []byte ("_r" ) indexPrefixSep = []byte ("_i" ) metaPrefix = []byte {'m' } sepPrefix = []byte {'_' } mdPrefix = append (metaPrefix, databasePrefix...) mdiPrefix = append (append (metaPrefix, databasePrefix...), indexPrefixSep...) mtPrefix = append (metaPrefix, tablePrefix...) mtiPrefix = append (append (metaPrefix, tablePrefix...), indexPrefixSep...) ) const ( idLen = 8 sepPrefixLen = 1 prefixLen = databasePrefixLength + idLen + sepPrefixLen + tablePrefixLength + idLen + recordPrefixSepLength uniqPrefixLen = databasePrefixLength + idLen + sepPrefixLen + tablePrefixLength + idLen + indexPrefixSepLength + idLen + sepPrefixLen indexPrefixLen = databasePrefixLength + idLen + sepPrefixLen + tablePrefixLength + idLen + indexPrefixSepLength + idLen + sepPrefixLen + sepPrefixLen indexPrefixLenWithID = databasePrefixLength + idLen + sepPrefixLen + tablePrefixLength + idLen + indexPrefixSepLength + idLen + sepPrefixLen + sepPrefixLen + idLen RecordRowKeyLen = prefixLen + idLen tablePrefixLength = 1 databasePrefixLength = 1 recordPrefixSepLength = 2 indexPrefixSepLength = 2 metaPrefixLength = 1 mdPrefixLen = metaPrefixLength + databasePrefixLength mdiPrefixLen = mdPrefixLen + indexPrefixSepLength mtPrefixLen = metaPrefixLength + tablePrefixLength mtiPrefixLen = mtPrefixLen + indexPrefixSepLength )
我们把rowkey的编码规则来看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func EncodeRowKey (databaseId, tableID, rowId int64 ) kv .Key buf := make ([]byte , 0 , prefixLen+idLen ) buf = append (buf, databasePrefix...) buf = append (buf, EncodeIdBuf(databaseId)...) buf = append (buf, sepPrefix...) buf = append (buf, tablePrefix...) buf = append (buf, EncodeIdBuf(tableID)...) buf = append (buf, recordPrefixSep...) buf = append (buf, EncodeIdBuf(rowId)...) return buf } func EncodeIdBuf (id int64 ) kv .Key var buf = make ([]byte , 8 ) binary.BigEndian.PutUint64(buf[:], uint64 (id)) return buf } func DecodeIdBuf (b []byte ) int64 return int64 (binary.BigEndian.Uint64(b)) }
这里我们通过EncodeRowKey(databaseId, tableID, rowId int64) kv.Key 来生成数据的row-key,我们利用make([]byte,0, len) 的方式预申请内存的方式,后面再通过append的方式往 slice 中不断追加字节,当遇到int64的数据的时候,我们会调用EncodeIdBuf(id int64) kv.Key 来把int64转换为 大端(网络字节序) 的二进制字节。最后一个row-key就生成了。
database 编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 type database struct { Id int64 Name string } func (s *Store) createDatabaseHandle (result *Result, stmt *ast.CreateDatabaseStmt) indexedKey := etccodec.EncodeDatabaseMetaIndexedKey([]byte (stmt.Name)) rdb := rocksdb.Load().(*Rocksdb) slice, err := rdb.Get(rdb.NewDefaultReadOptions(), indexedKey) if err != nil { errorlog(UnexpectErrorCategory{}, UnknowRCode) result.Record(UnknowRCode, nil ) return } if slice.Exists() { if !stmt.IfNotExists { errorlog(UnexpectErrorCategory{}, DatabaseExistsRCode) result.Record(DatabaseExistsRCode, nil ) } else { result.Success() } return } dbId, err := getDatabaseId() if err != nil { msg := fmt.Sprintf("get database id failed, err: %s" , err) errorlog(UnexpectErrorCategory{}, msg) result.Record(CreateDatabaseFailedRCode, &msg) return } db := &database{ Id: dbId, Name: stmt.Name, } var buf = etccodec.EncodeIdBuf(dbId) key := etccodec.EncodeDatabaseMetaKey(dbId) value, err := json.Marshal(db) if err != nil { msg := fmt.Sprintf("marshal database error, err: %s" , err) errorlog(UnexpectErrorCategory{}, msg) result.Record(CreateDatabaseFailedRCode, &msg) return } err = rdb.Put(key, value) if err != nil { msg := fmt.Sprintf("rocksdb put metadata failed, err: %s" , err) errorlog(UnexpectErrorCategory{}, msg) result.Record(CreateDatabaseFailedRCode, &msg) return } err = rdb.Put(indexedKey, buf) if err != nil { msg := fmt.Sprintf("rocksdb put indexed failed, err: %s" , err) errorlog(UnexpectErrorCategory{}, msg) result.Record(CreateDatabaseFailedRCode, &msg) return } debugf(NormalDebugCategory{}, "create database [%s]" , db) result.Success() }
这里,我们借助 create database stmt 来的处理方法来看看 db Key-Value pair 的处理逻辑。stmt.Name 来拿到数据库的名,并且调用etccodec.EncodeDatabaseMetaIndexedKey([]byte(stmt.Name)) 方法来创建符合metaPrefix(+)databasePrefix_indexPrefix{database_name} 索引的key,然后判断是否存在所以索引来判断后续的逻辑。getDatabaseId() 方法来获取一个全局的数据库id,并且初始化type database struct,然后我们调用了 etccodec.EncodeDatabaseMetaKey(dbid) 来对key进行生成,也就是上面所列出来的 metaPrefix(+)databasePrefix{dbID}, 接下来就是value的生成,这里的value比较直接,就是json.marshal来处理后的字节。然后我们把数据put 到rocksdb就结束了,索引数据也是如此,不过索引存储的dbid。
table的编码也类似
如果对其他的stmt,例如insert stmt/delete stmt具体的逻辑感兴趣的话,可以查阅源码,但是类似差不多。
COUNTER计数器-发号器 这里我们需要讲一下counter,因为我们所有的数据都会有row_id,并且我们在create table的时候也有AUTO_INCREMENT的列,这个时候,我们也是需要一个ID发号器。
目前常见的发号器实现方案如下:
UUID
snowflake
数据库生成
美团的Leaf(基于数据库)
UUID UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace
由于他的无序性,不符合我们所期待的增长序列,所以抛弃
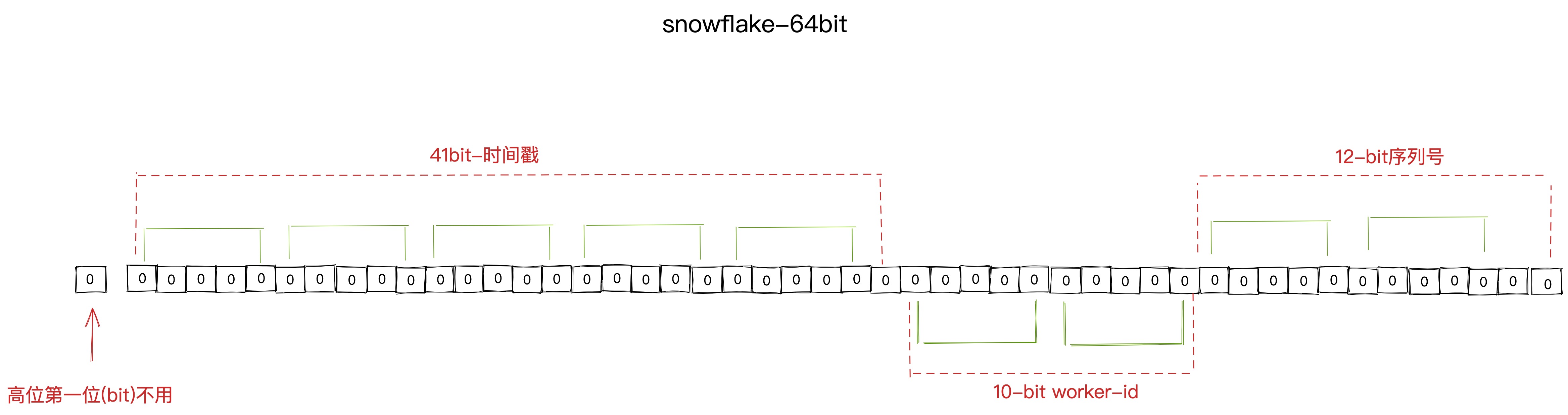
类snowflake方案 这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图所示:
生成繁琐,由多个指令码组成,并且我们不需要用到分布式,这个还对本地的时间有强依赖,不够简洁
基于数据库的 基于数据库的其实就是利用自增的自增机制+发号机制的组合,但是由于我们这里不基于数据库,所以给予数据库的基本也不考虑,但是其中的发号机制可以参考。例如:预分配机制。
自己的发号器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 package msourceimport ( "fmt" "gitlab.mingchao.com/basedev-deps/gorocksdb" "os" "os/signal" "reflect" "strconv" "syscall" "time" ) type counter struct { *gorocksdb.ReadOptions IdKey []byte GroupId string idChan chan int64 sig chan os.Signal } func (c *counter) UnmarshalJSON (data []byte ) (err error) c.IdKey = data[1 : len (data)-1 ] turboNew(c) return } func (c *counter) MarshalJSON () ([]byte , error) b := make ([]byte , 0 , len (c.IdKey)+2 ) b = append (b, '"' ) b = append (b, c.IdKey...) b = append (b, '"' ) return b, nil } func (c *counter) String () string t := reflect.TypeOf(c).Elem() v := reflect.ValueOf(c).Elem() p := fmt.Sprintf("%s {" , t.Name()) for i := 0 ; i < v.NumField(); i++ { if v.Field(i).CanInterface() { if v.Field(i).Kind() == reflect.Slice { p += fmt.Sprintf("\n\t %s(%s): %s" , t.Field(i).Name, t.Field(i).Type, string (v.Field(i).Bytes())) } else { p += fmt.Sprintf("\n\t %s(%s): %v" , t.Field(i).Name, t.Field(i).Type, v.Field(i).Interface()) } } } p += "\n}" return p } func NewCounter (prefix string ) *counter return newCounter(prefix) } func newCounter (prefix string , args ...interface {}) *counter c := new (counter) if len (args) > 0 { c.GroupId = args[0 ].(string ) } c.IdKey = []byte (fmt.Sprintf("%s:%s" , prefix, c.GroupId)) turboNew(c) return c } func turboNew (c *counter) ct := custom.Load().(*Custom) c.idChan = make (chan int64 , ct.IdStep) c.sig = make (chan os.Signal, 1 ) c.ReadOptions = gorocksdb.NewDefaultReadOptions() signal.Notify(c.sig, syscall.SIGINT, syscall.SIGTERM) c.sender() } func (c *counter) sender () go func () ct := custom.Load().(*Custom) for { select { case <-c.sig: close (c.idChan) return default : if len (c.idChan) < ct.IdStep/10 { rdb := rocksdb.Load().(*Rocksdb) if c.ReadOptions == nil { c.ReadOptions = gorocksdb.NewDefaultReadOptions() } slice, err := rdb.Get(c.ReadOptions, c.getIdKey()) if err != nil { fatal(UnexpectErrorCategory{"counter sender error" }, err) } else { var idStr string if slice.Exists() && slice.Size() > 0 { idStr = string (slice.Data()) } else { idStr = "0" } cid, err := strconv.ParseInt(idStr, 10 , 64 ) if err != nil { fatal(UnexpectErrorCategory{"counter sender error" }, err) } else { ct := custom.Load().(*Custom) if ((1 <<63 -1 )/2 )-ct.IdStep < ct.IdStep { cid = 0 } nextId := cid + int64 (ct.IdStep) err = c.ackId(nextId) if err != nil { fatal(UnexpectErrorCategory{"counter sender error" }, err) } for cid < nextId { cid++ c.idChan <- cid } } } } else { time.Sleep(50 * time.Millisecond) } } } }() } func (c *counter) getId () (int64 , error) id := <-c.idChan return id, nil } func (c *counter) GetId () (int64 , error) return c.getId() } func (c *counter) ackId (id int64 ) error rdb := rocksdb.Load().(*Rocksdb) err := rdb.Put(c.getIdKey(), []byte (strconv.FormatInt(id, 10 ))) if err != nil { return err } return nil } func (c *counter) AckId (id int64 ) error return c.ackId(id) } func (c *counter) getIdKey () []byte return c.IdKey }
这里我们优先考虑可以通过内存直接通过++或者+1操作符分配的方式。我们重点看到:
1 2 3 4 5 6 nextId := cid + int64 (ct.IdStep) err = c.ackId(nextId) for cid < nextId { cid++ c.idChan <- cid }
可以再这里看到,我们通过拿到当前cid的数值,通过idStep来增加固定的步长,然后先通过回写nextId的值到rocksdb进行持久化,再通过for循环来对cid进行叠加,每次都推送到有缓冲区的idChan中。
1 2 3 4 5 6 7 8 9 func (c *counter) getId () (int64 , error) id := <-c.idChan return id, nil } func (c *counter) GetId () (int64 , error) return c.getId() }
通过 func (c *counter) getId() (int64, error) 来消费idChan中的id,达到一个获取id的效果。
1 2 3 4 if ((1 <<63 -1 )/2 )-ct.IdStep < ct.IdStep { cid = 0 }
我们看到这里有一行代码,当int64的cid已经到达分配的极限了,那么cid就会进行回滚,基本保证了发号的可重复利用性。
扩展问题:id回溯了,怎么做递增判断?
这个问题其实有点类似tcp的syn回溯的问题。因为syn一开始是随机生成的,并且这个过程了syn是会不断增加的。当syn到达分配的极限进行了回溯的时候,如何比较大小?
我们查看到内核的tcp源码,可以看到提供的判断方式十分巧妙,如下:
1 2 3 4 5 6 7 8 9 static inline int before (__u32 seq1, __u32 seq2) return (__s32)(seq1-seq2) < 0 ;} #define after(seq2, seq1) before(seq1, seq2)
为什么(__s32)(seq1-seq2)<0就可以判断seq1<seq2呢?这里的__s32是有符号整型的意思,而__u32则是无符号整型。unsigned char和char为例来说明:
假设seq1=255, seq2=1(发生了回绕)seq1<seq2
1 2 3 4 5 seq1 - seq2= 1111 1111 -0000 0001 ----------- 1111 1110
由于我们将结果转化成了有符号数,由于最高位是1,因此结果是一个负数,负数的绝对值为
因此 seq1 - seq2 < 0
注意:
如果seq2=128的话,我们会发现:
1 2 3 4 5 seq1 - seq2= 1111 1111 -1000 0000 ----------- 0111 1111
此时结果尤为正了,判断的结果是seq1>seq2。因此,上述算法正确的前提是,回绕后的增量小于2^(n-1)-1。
由于tcp序列号用的32位无符号数,因此可以支持的回绕幅度是2^31-1,满足要求了。
但是由于我们这里不需要比较发号的先后次序,只需要保证其唯一性,所以这个回溯的大小比较问题,并不需要过多的关注
行级锁的实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 var ( rowLockLock sync.RWMutex rowLock rl ttlTime = int64 (30 * 60 ) ) type ( rl map [string ]*lock lock struct { ttl int64 lock sync.RWMutex } } func init () go func () t := time.NewTicker(10 * time.Minute) for { select { case <-t.C: ct := time.Now().Unix() rowLockLock.Lock() for key, lock := range rowLock { if ct > lock.ttl { delete (rowLock, key) } } rowLockLock.Unlock() } } }() rowLock = make (rl, 10 ) } func rowLockKey (dbId, tblId, rowId int64 ) string return fmt.Sprintf("%d:%d:%d" , dbId, tblId, rowId) } func (r *rl) Lock (lockKey string ) rowLockLock.Lock() m, ok := (*r)[lockKey] if !ok { m = new (lock) (*r)[lockKey] = m m.ttl = time.Now().Unix() + ttlTime } rowLockLock.Unlock() m.lock.Lock() } func (r *rl) UnLock (lockKey string ) rowLockLock.Lock() m, ok := (*r)[lockKey] if !ok { m = new (lock) (*r)[lockKey] = m m.ttl = time.Now().Unix() + ttlTime } rowLockLock.Unlock() m.lock.Unlock() } func (r *rl) RLock (lockKey string ) rowLockLock.Lock() m, ok := (*r)[lockKey] if !ok { m = new (lock) (*r)[lockKey] = m m.ttl = time.Now().Unix() + ttlTime } rowLockLock.Unlock() m.lock.RLock() } func (r *rl) RUnlock (lockKey string ) rowLockLock.Lock() m, ok := (*r)[lockKey] if !ok { m = new (lock) (*r)[lockKey] = m m.ttl = time.Now().Unix() + ttlTime } rowLockLock.Unlock() m.lock.RUnlock() }
以上是行级锁的实现方式,主要是利用sync.RWMutex来实现读写锁,并且带有ttl的机制,每次加锁的时候,都会更新ttl的时间。init阶段,我们利用的ticker来实现对锁进行一个类似LRU的机制,对于不活跃的锁对象进行释放,防止在这里造成内存只增不减。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (s *Store) updateHandle (result *Result, stmt *ast.UpdateStmt) .... rowID, _ := item[0 ].(json2.Number).Int64() rowlockKey := rowLockKey(db.Id, tbl.Id, rowID) rowLock.Lock(rowlockKey) defer rowLock.UnLock(rowlockKey) for _, index := range indexs { ... } ... }
逆波兰表达式 && 波兰表达式 这一块其实暂时还没实现,但是他的原理有必要和大家说一下,我们的db实现,都是基于sql 来实现的,我们知道 sql 中也有表达式计算,并且是有优先级之分的。
前/中/后序遍历,相信大家基本都听说过,但是实际运用中少之又少,这是因为大家可能在实际中没有找到合适的模式和套用这些树的遍历方式。
前序遍历:根结点 —> 左子树 —> 右子树
中序遍历:左子树—> 根结点 —> 右子树
后序遍历:左子树 —> 右子树 —> 根结点
例如:
1 SELECT (count * price) AS sum FROM orders WHERE order_id < 100
其中 order_id < 10 就是一个表达式,它有一个列输入参数: order_id,输出:Bool
RPN 表达式(逆波兰表示法) RPN 是树的后序遍历,后序遍历在每个节点知道自己有几个子节点的时候等价于原本的树结构。
所以你波澜是后序遍历:左右中
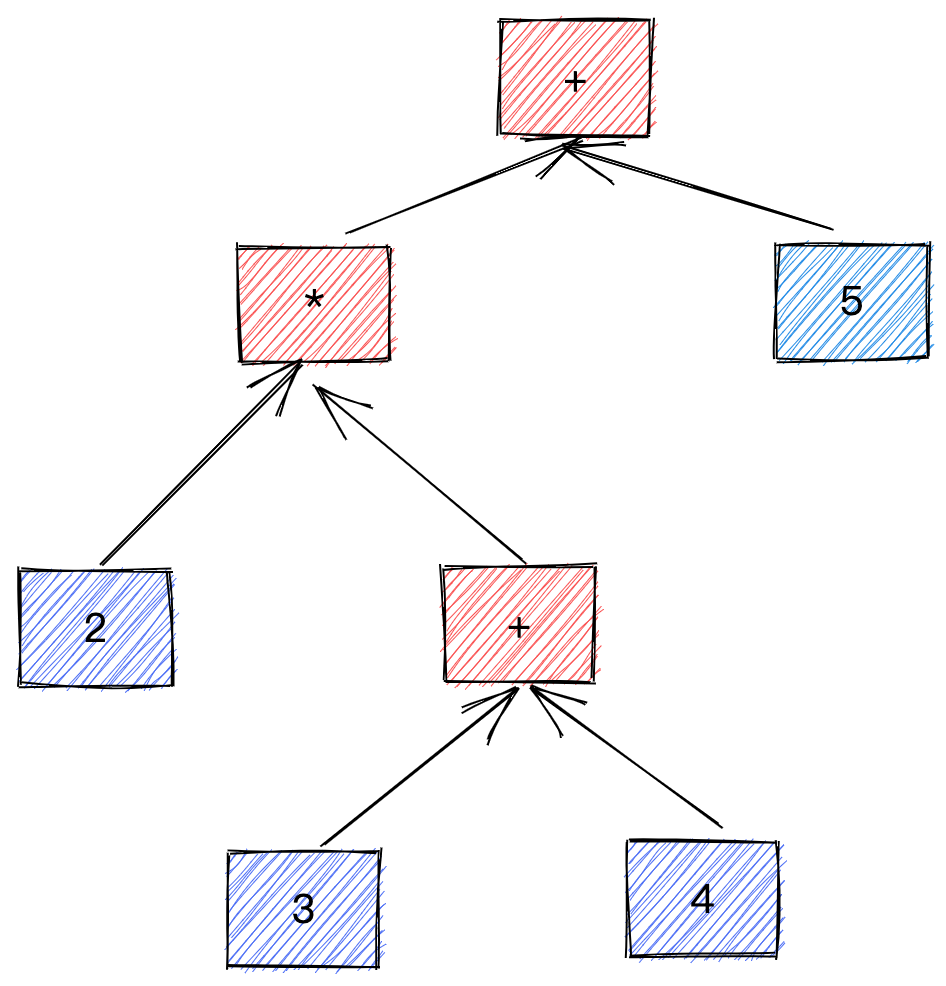
比如说我们有一个数学算式 2 *(3 + 4)+ 5:
由于数学上习惯写法是中序遍历,我们通常要加上括号消除歧义(比如加减和乘除的顺序)。通过把操作符后移 我们得到 RPN:2 3 4 + * 5 +,这样我们无需括号就能无歧义地遍历这个表达式:
中序表达式转后序表达式:
1 2 3 4 原式:a+b*(c+d/e) 补全括号:(a+(b*(c+(d/e)))) 操作符右移:(a(b(c(de)/)+)*)+ 去掉括号:abcde/+*+
所以波兰表达式是中序遍历:左右中
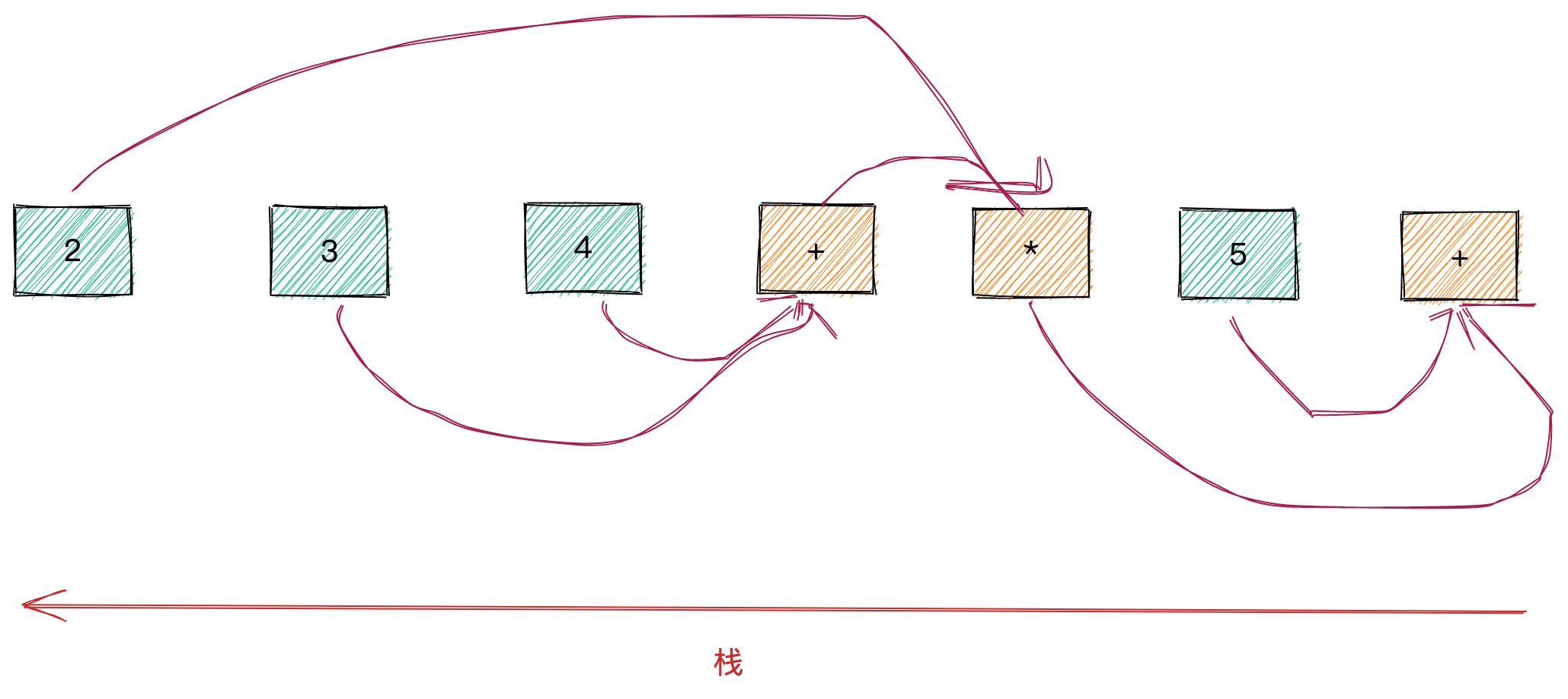
执行 RPN 的过程需要一个栈来缓存中间结果,比如说对于 2 3 4 + * 5 +,我们从左到右遍历表达式,遇到值就压入栈中。直到 + 操作符,栈中已经压入了 2 3 4。
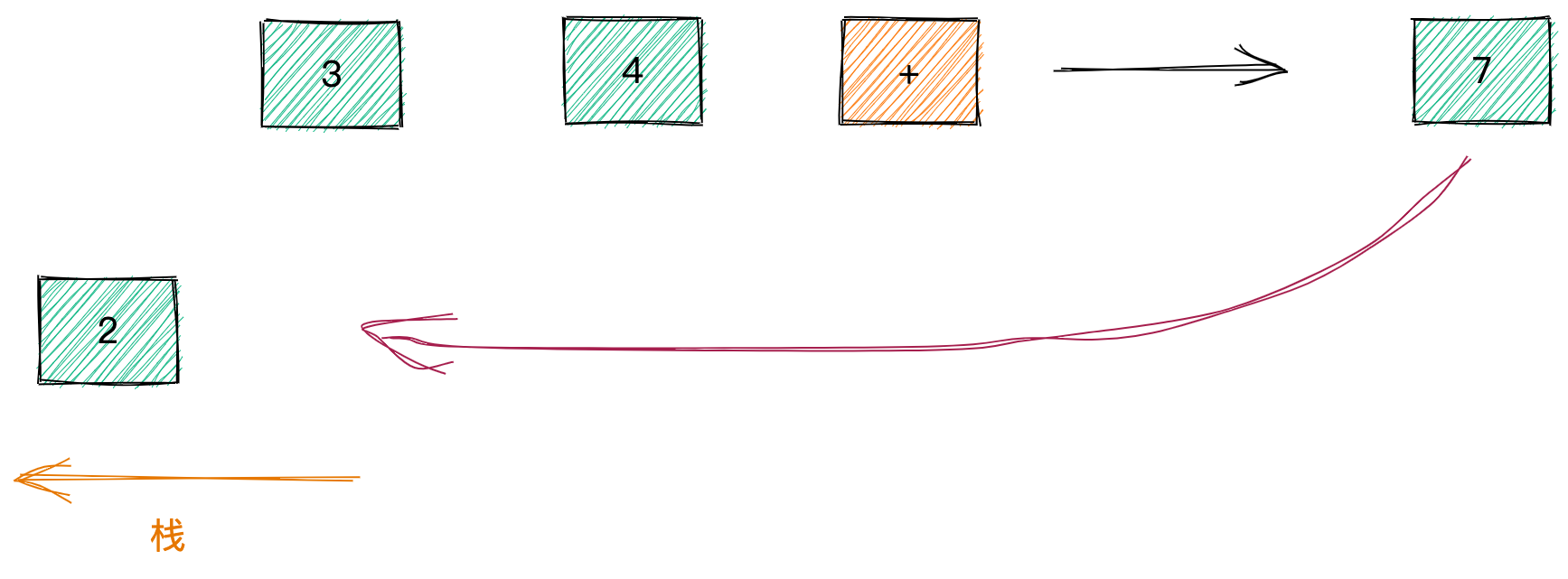
因为 + 是二元操作符,需要从栈中弹出两个值 3 4,结果为 7,重新压入栈中:
此时栈中的值为 2 7。
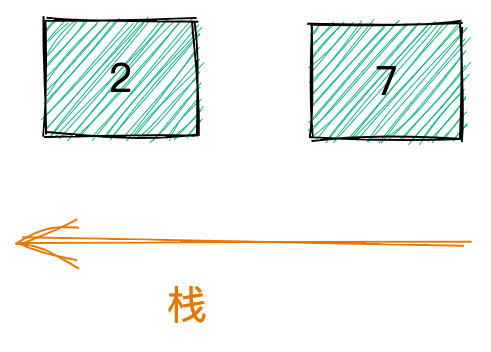
下一个是 * 运算符,也需要弹出两个值 2 7,结果为 14 压入栈中。
接着压入 5 。
最后 + 运算符弹出 14 5,结果为 19 ,压入栈。
最后留在栈里的就是表达式的结果,因此,如果需要计算表达式优先级的话,可以采用RPN的方式来读取tree结构来进行顺序计算。
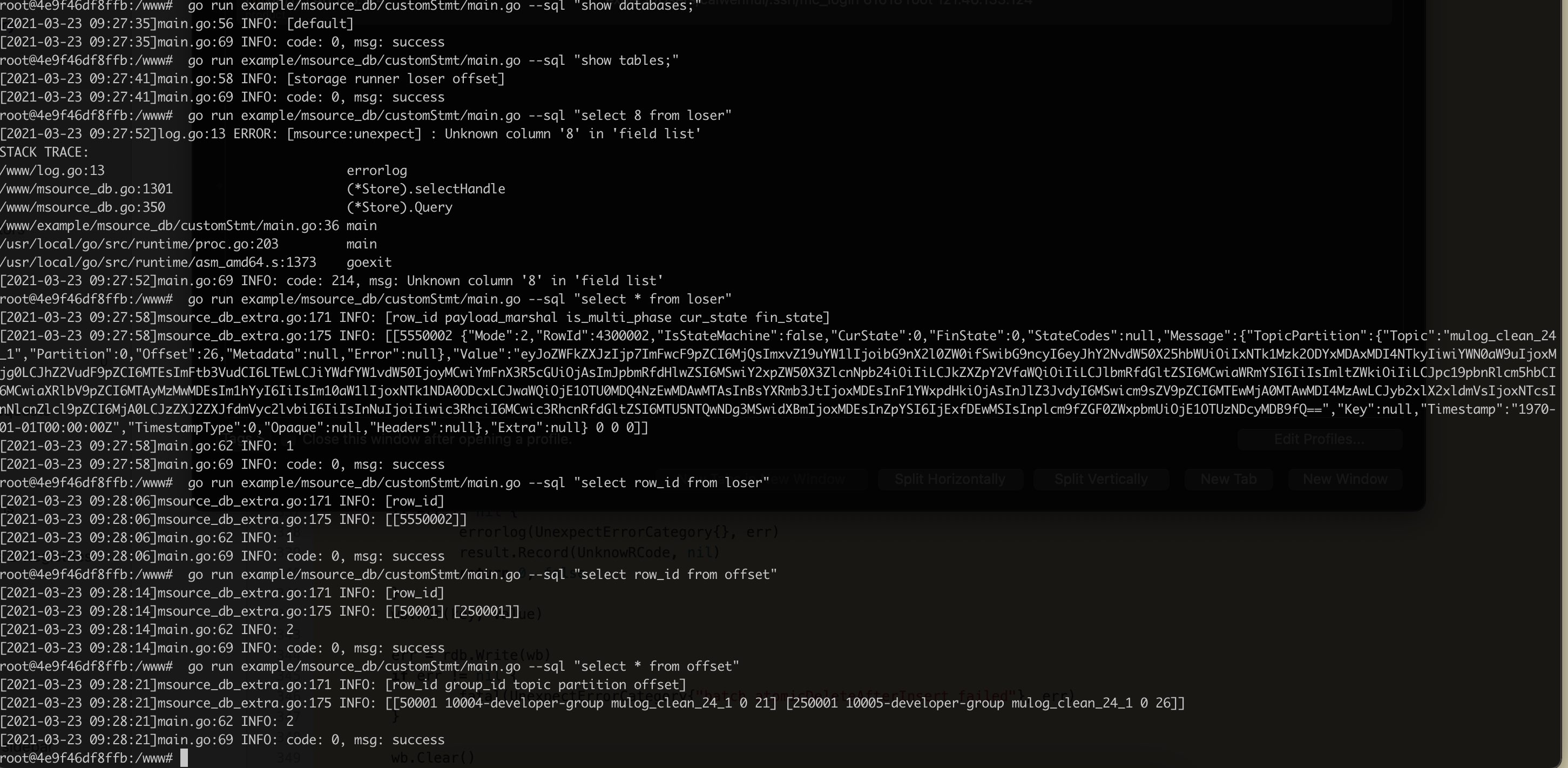
单独使用DB例子:
这里有一个类似于mysql-client 的一个 bin 程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 package mainimport ( "flag" "github.com/pingcap/parser" "github.com/pingcap/parser/ast" "gitlab.mingchao.com/basedev-deps/logbdev" "gitlab.mingchao.com/basedev-deps/msource/v2" "os" ) var sql = flag.String("sql" , "" , "Input Your Sql" )func init () flag.Parse() } func main () if os.Getenv("DEBUG" ) == "true" { logbdev.SetLevel(logbdev.DebugLevel) } msource.PreparePhase() store := msource.NewStore() p := parser.New() stmtNode, err := p.ParseOneStmt(*sql, "" , "" ) if err != nil { logbdev.Error(err) return } _, ok := stmtNode.(*ast.SelectStmt) var r *msource.Result if ok { r, err = store.Query(*sql) if err != nil { logbdev.Error(err) return } } else { r, err = store.Execute(*sql) if err != nil { logbdev.Error(err) return } } if r != nil { if r.Data != nil { switch ar := r.Data.(type ) { case *msource.InsertResultData: logbdev.Info(ar.GetSliceInt64()) logbdev.Info(ar.Raw()) case *msource.ShowDatabasesResultData: logbdev.Info(ar.GetSliceString()) case *msource.ShowTablesResultData: logbdev.Info(ar.GetSliceString()) case *msource.SelectResultSetData: logbdev.Info(ar.GetFields()) logbdev.Info(ar.GetValues()) logbdev.Info(ar.Count()) case *msource.DeleteResultData: logbdev.Info(ar.GetAffected()) case *msource.UpdateResultData: logbdev.Info(ar.GetAffected()) } } logbdev.Info(r) } }
具体用法:
1 2 3 4 5 go run example/msource_db/customStmt/main.go --sql "INSERT INTO users(\`name\`,\`age\`,\`last_login\`) VALUES (\"caiwenhui\", 18, 1614776101)" go run example/msource_db/customStmt/main.go --sql "show databases;" go run example/msource_db/customStmt/main.go --sql "show tables;" go run example/msource_db/customStmt/main.go --sql "INSERT INTO mingchao.users2(\`name\`,\`age\`) VALUES (\"caiwenhui\", 18),(\"caiwenhui\", 19)" go run example/msource_db/customStmt/main.go --sql "INSERT INTO mingchao.users2 VALUES (1000,\"caiwenhui\", 18)"
我们可以用对外暴露一个msource.NewStore()来创建一个存储器对象,然后通过API进行数据库的操作。
NewStore我们用了sync.Pool封装,对象可以做到尽可能的复用。
可以看到如果是SELECT STMT的话,我们调用的是QUERYAPI,如果是非SELECT STMT的话,我们调用的是EXECUTEAPI。
TODO 基于目前尚未实现,所以暂时不再展开讲叙,后续可以升级处理的点为:
事务处理,例如前面所说的redolog和undolog可实现。
orderby, 数据排序。
全双工的通信获取数据,无需一次性读取所有数据。
Explain执行计划的实现,逻辑根据执行计划走。
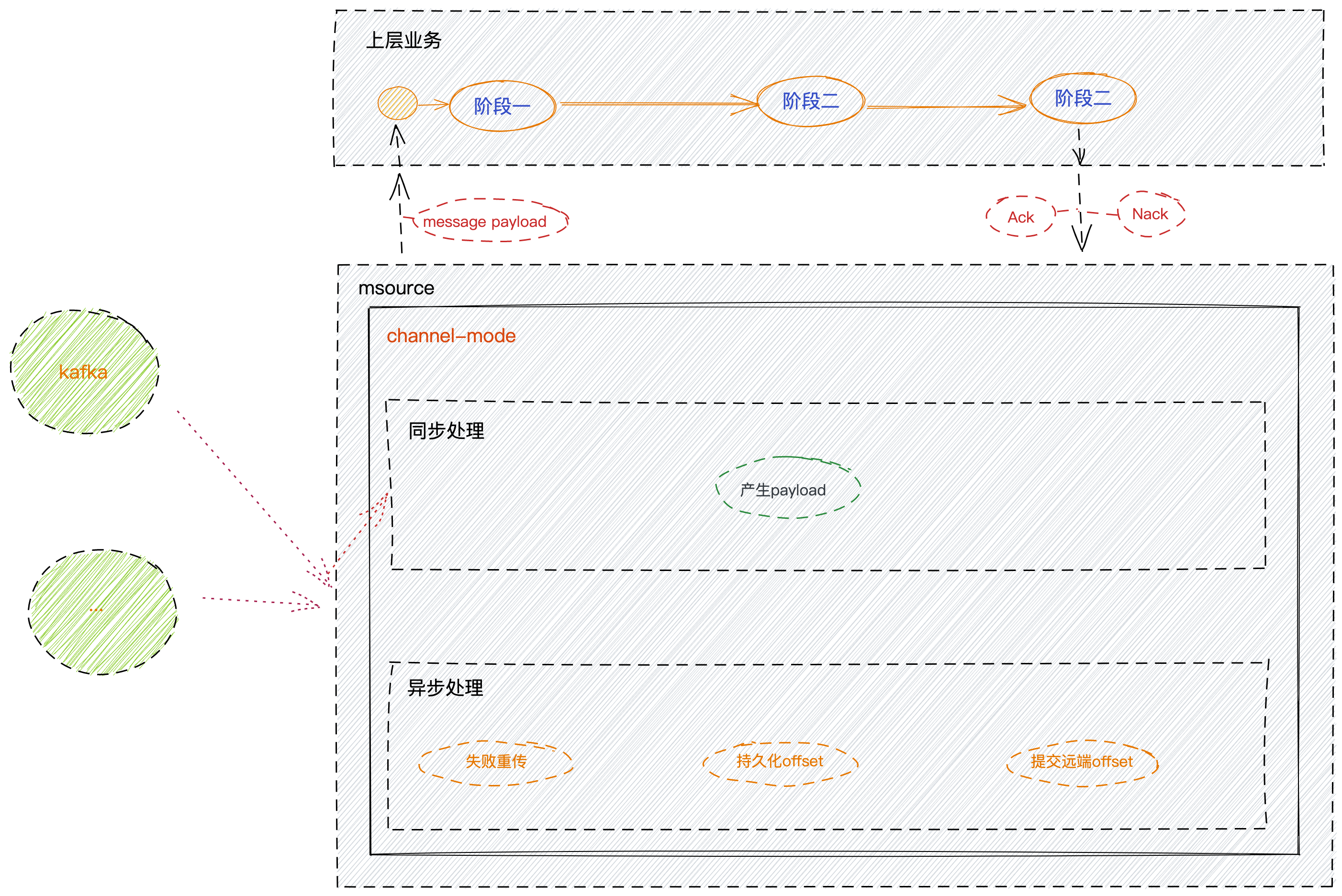
SPOUT 另外一篇文章中,记录了我们的spout的作用,在这里,再简单说一下,spout 是我们msource组件的核心角色,它是用于把数据推送到上层业务的所使用。上层业务通过spout角色提供的API,可以获取到从数据源拿到的数据。
spout 自身保持了一套 高可靠, 高性能, 可容错 的数据机制,主要用于区别出ACK, NACK,并且自带有 失败重传, 多阶段状态机的checkpoint等机制。
channel-mode 大体数据流程图
之前有一篇文章,专门讲解channel-mode下,是如何工作的,这里不做过多详细的说明。简单复述一下。
channel模式下,是直接把数据推送到我们的golang的channel 当中,上层业务直接用过channel拿到数据,拿到数据后根据自身业务处理数据来判断可以ack或者nack掉数据,同时保存offset。
这里的问题就在于:
由于我们是本地存储的offset,因为不信任 kafka-client的auto-commit机制,当程序在某个节点crash的时候,这会让我们的程序在下次启动的时候,重复消费到数据或者遗漏数据
缺点:每个partition的offset都需要顺序消费,在上层业务无法并发处理,这极大程度的降低了我们的消费效率
期望:如果我们提前把offset存储起来了,而不需要ACK之后再存储offset的话,那么我们就可以再上层业务并发的处理消息,而无需关注offset的问题
db-demo 大体数据流程图
鉴于channel-mode下的缺点,由此诞生了我们的db-mode,其原理是把数据先存储在本地的数据库,也就是我们上面所说的db,所以这里我们可以得出关系spout <- db, db角色 可以被 spout角色所依赖。
我们创建了4个表来存储不同的数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 const ( DefaultDatabase = "default" DefaultDatabaseSql = "CREATE DATABASE IF NOT EXISTS `" + DefaultDatabase + "`" UseDefaultDatabase = "USE `" + DefaultDatabase + "`" SpoutStoreStorageTable = "storage" SpoutStoreStorageBuildTableSql = "create table if not exists " + SpoutStoreStorageTable + "(" + " `payload_marshal` varchar(255) not null comment \"序列化后的payload\"," + " `is_multi_phase` int(11) not null default 0 comment \"是否多阶段,0=否, 1=是\"," + " `cur_state` int(11) not null default 0 comment \"当前状态\"," + " `fin_state` int(11) not null default 0 comment \"最终状态\"" + ")" SpoutStoreRunningTable = "runner" SpoutStoreRunningBuildTableSql = "create table if not exists " + SpoutStoreRunningTable + "(" + " `payload_marshal` varchar(255) not null comment \"序列化后的payload\"," + " `is_multi_phase` int(11) not null default 0 comment \"是否多阶段,0=否, 1=是\"," + " `cur_state` int(11) not null default 0 comment \"当前状态\"," + " `fin_state` int(11) not null default 0 comment \"最终状态\"" + ")" SpoutStoreLoserTable = "loser" SpoutStoreLoserBuildTableSql = "create table if not exists " + SpoutStoreLoserTable + "(" + " `payload_marshal` varchar(255) not null comment \"序列化后的payload\"," + " `is_multi_phase` int(11) not null default 0 comment \"是否多阶段,0=否, 1=是\"," + " `cur_state` int(11) not null default 0 comment \"当前状态\"," + " `fin_state` int(11) not null default 0 comment \"最终状态\"" + ")" SpoutStoreDefaultOffsetTable = "offset" SpoutStoreDefaultOffsetBuildTableSql = "create table if not exists " + SpoutStoreDefaultOffsetTable + "(" + " `group_id` varchar(255) not null comment \"消费组\"," + " `topic` varchar(255) not null comment \"消费的topic\"," + " `partition` int(11) not null comment \"topic的partition\"," + " `offset` int(11) not null comment \"当前消费的offset\"," + " UNIQUE KEY `uniq_idx` (`group_id`,`topic`,`partition`)" + ")" )
DB模式下的用法例子:
channel-mode下的例子和db模式的差不多,但是更加简单,这里就不列出来了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 package commonimport ( "context" "gitlab.mingchao.com/basedev-deps/logbdev" "gitlab.mingchao.com/basedev-deps/msource/v2" "os" "os/signal" "sync" "syscall" ) func PreparePhase () logbdev.SetLevel(logbdev.DebugLevel) S = msource.PreparePhase() } var S *msource.Spoutfunc CoreStart (function func (payload *msource.Payload) ) wg := new (sync.WaitGroup) ctx, cannel := context.WithCancel(context.Background()) S.Start(ctx) sig := make (chan os.Signal, 1 ) signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM) wg.Add(1 ) go func () defer wg.Done() for { select { case <-sig: cannel() return } } }() innerWorker := 3 logbdev.Infof("total chan: %d\n" , S.ChanSize()) for i := 0 ; i < S.ChanSize(); i++ { for ii := 0 ; ii < innerWorker; ii++ { wg.Add(1 ) go func (idx, idx2 int ) defer wg.Done() logbdev.Infof("start chan[%d-%d]\n" , idx, idx2) payloadCh := S.GetPayloadChanById(idx) for payload := range payloadCh.GetCh() { function(payload) } }(i, ii) } } wg.Wait() S.Stop() }
ACK 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport ( "gitlab.mingchao.com/basedev-deps/logbdev" "gitlab.mingchao.com/basedev-deps/msource/v2" "gitlab.mingchao.com/basedev-deps/msource/v2/example/spout/db/common" ) func main () common.CoreStart(func (payload *msource.Payload) if err := common.S.Ack(payload); err != nil { logbdev.Error(err) } }) }
NACK 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ( "gitlab.mingchao.com/basedev-deps/logbdev" "gitlab.mingchao.com/basedev-deps/msource/v2" "gitlab.mingchao.com/basedev-deps/msource/v2/example/spout/db/common" ) func main () common.PreparePhase() common.CoreStart(func (payload *msource.Payload) if err := common.S.MarkFailure(payload); err != nil { logbdev.Error(err) } }) }
STATE-MACHINE 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 package mainimport ( "context" "fmt" "gitlab.mingchao.com/basedev-deps/logbdev" "gitlab.mingchao.com/basedev-deps/msource/v2/example/spout/db/common" "os" "os/signal" "sync" "syscall" ) type MyStateMachine struct { phases []string } func (msm *MyStateMachine) AddPhase (name string ) error msm.phases = append (msm.phases, name) return nil } func (msm *MyStateMachine) GetPhases () []string return msm.phases } func main () common.PreparePhase() wg := new (sync.WaitGroup) ctx, cannel := context.WithCancel(context.Background()) sms := &MyStateMachine{} _ = sms.AddPhase("step1" ) _ = sms.AddPhase("step2" ) _ = sms.AddPhase("step3" ) common.S.SetStateMachine(sms) common.S.Start(ctx) sig := make (chan os.Signal, 1 ) signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM) wg.Add(1 ) go func () defer wg.Done() for { select { case <-sig: cannel() return } } }() logbdev.Infof("total chan: %d\n" , common.S.ChanSize()) for i := 0 ; i < common.S.ChanSize(); i++ { wg.Add(1 ) chCtx, _ := context.WithCancel(ctx) go func (idx int , childCtx context.Context) defer wg.Done() logbdev.Infof("start chan[%d]\n" , idx) payloadCh := common.S.GetPayloadChanById(idx) for { select { case payload := <-payloadCh.GetCh(): var wg sync.WaitGroup wg.Add(1 ) go func () defer wg.Done() phase := "step1" if common.S.CanTransition(payload, phase) { fmt.Println("Do Step 1 something" ) _ = common.S.Transition(payload, phase) } }() wg.Add(1 ) go func () defer wg.Done() phase := "step2" if common.S.CanTransition(payload, phase) { fmt.Println("Do Step 2 something" ) _ = common.S.Transition(payload, phase) } }() wg.Add(1 ) go func () defer wg.Done() phase := "step3" if common.S.CanTransition(payload, phase) { fmt.Println("Do Step 3 something" ) _ = common.S.Transition(payload, phase) } }() wg.Wait() case <-ctx.Done(): fmt.Println("Done" ) return } } }(i, chCtx) } wg.Wait() common.S.Stop() }
小知识总结 time组件 在开发的过程中,time组件用得还是比较多的,因为有各种异步任务在后台运行,常规的用法就不记录讲述了,这里说一下一些注意的点。
1 2 3 4 5 6 7 8 9 // After waits for the duration to elapse and then sends the current time // on the returned channel. // It is equivalent to NewTimer(d).C. // The underlying Timer is not recovered by the garbage collector // until the timer fires. If efficiency is a concern, use NewTimer // instead and call Timer.Stop if the timer is no longer needed. func After(d Duration) <-chan Time { return NewTimer(d).C }
我们看到这个API,如果想要用
1 2 3 4 5 6 7 8 for { select { case <-time.After(1 *time.Second)): fmt.Println("时间到了" ) default : fmt.Println("go on" ) } }
看到这个例子,如果我们这么用的话,每1秒都会重新创建一个Timer对象,不断在堆空间申请内存,然后gc-worker再大量回收没有再使用的对象内存。这就导致cpu做了额外的一些无效工作。
所以这种用法我是不推荐的。
1 2 3 4 5 6 7 func (t *Timer) Reset (d Duration) bool if t.r.f == nil { panic ("time: Reset called on uninitialized Timer" ) } w := when(d) return resetTimer(&t.r, w) }
我们看到其实Timer 其实有一个Reset的API,我们可以对同一个timer进行Reset的操作,不断是重置时间即可。
1 2 3 4 5 6 7 8 9 10 d := 1 *time.Second t:= NewTimer(d) for { select { case <-t.C: t.Reset(d) default : fmt.Println("go on" ) } }
make函数 make函数是一个很强大的函数,我们会经常使用到,但是有一些细节,需要大家知道的。
make([]byte,0,10) 与 make([]byte,10) 这是2中不同的切片,对于可能刚学习golang的小伙伴来说,会有点疑惑,但是这是需要了解的,如果是三个参数的时候,一个是cap,一个是len,他们是有区别的。如果是三个参数的话,那代表当前大小cap = len
我们经常会用三个参数来进行预分配空间,第二个参数默认都是填写0来进行优化,特别是我们在写DB的时候,用到了大量[]byte类型,在组装编码字节的时候,我们就需要使用这种方式来处理,否则。
1 2 3 4 5 a := make ([]byte , 0 , 5 ) a = append (a, []byte {'a' }) a := make ([]byte , 5 ) a = append (a, []byte {'a' })
看到这里,大家就会明白区别。
once函数 有些时候,我们想要保证只运行一次,这里,我们就需要借助 sync.Once,需要注意的是 一个sync.Once只能与一个函数绑定!
1 2 3 4 5 6 7 once := new (sync.Once) callback:= func () "我只想运行一次" )} once.Do(callback) once.Do(callback) once.Do(callback) once.Do(callback)
自定义marshal和unmarshal 有时候,我们想要自己定义json的marshal 和 unmarshal,这里我们的发号计数器 就用到了,用它的原因其实是因为,我们的发号计数器在发号的过程中,其实是后台跑着一个异步任务在发号,所以在被反编码的时候,我们需要启动这个异步任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func (c *counter) UnmarshalJSON (data []byte ) (err error) c.IdKey = data[1 : len (data)-1 ] turboNew(c) return } func (c *counter) MarshalJSON () ([]byte , error) b := make ([]byte , 0 , len (c.IdKey)+2 ) b = append (b, '"' ) b = append (b, c.IdKey...) b = append (b, '"' ) return b, nil } func turboNew (c *counter) ct := custom.Load().(*Custom) c.idChan = make (chan int64 , ct.IdStep) c.sig = make (chan os.Signal, 1 ) c.ReadOptions = gorocksdb.NewDefaultReadOptions() signal.Notify(c.sig, syscall.SIGINT, syscall.SIGTERM) c.sender() } func (c *counter) sender () ... }
lockfree-queue和lockfree-stack 我们知道如果想要做到并发安全的话,普遍做法就是2种
无锁化结构的设计(需要针对特定的业务常用,并且不允许乱用)
有锁结构
无锁化(lock-free)的实现方式有很多种,在开发的过程中,我也有想过利用lock-free-stack以及lock-free-queue,分别想要运用在RPN的实现以及发号器当中,虽然后来发现用不到,但是可以拿到这里和大家分享一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 func inrInt64 (i *int64 ) t := int64 (+1 ) for { value := atomic.LoadInt64(i) if atomic.CompareAndSwapInt64(i, value, value+t) { return } time.Sleep(time.Nanosecond) } } func dcrInt64 (i *int64 ) t := int64 (-1 ) for { value := atomic.LoadInt64(i) if atomic.CompareAndSwapInt64(i, value, value+t) { return } time.Sleep(time.Nanosecond) } } func NewLKStack () *LKStack n := unsafe.Pointer(&node{}) return &LKStack{head: n} } type LKStack struct { len int64 head unsafe.Pointer } func (q *LKStack) IsEmpty () bool return q.Len() == 0 } func (q *LKStack) Len () int64 return q.len } func (q *LKStack) Push (v interface {}) n := &node{value: v} for { head := load(&q.head) next := load(&n.next) cas(&n.next, next, head) if cas(&q.head, head, n) { inrInt64(&q.len ) return } time.Sleep(time.Nanosecond) } } func (q *LKStack) Pop () interface for { head := load(&q.head) next := load(&head.next) if next == nil { return nil } else { v := head.value if cas(&q.head, head, next) { dcrInt64(&q.len ) return v } } time.Sleep(time.Nanosecond) } } func load (p *unsafe.Pointer) (n *node) return (*node)(atomic.LoadPointer(p)) } func cas (p *unsafe.Pointer, old, new *node) (ok bool ) return atomic.CompareAndSwapPointer( p, unsafe.Pointer(old), unsafe.Pointer(new )) }
这里也不过多在这里描述了,我们大家查看源码吧,主要就是利用了atomic包中的原子性操作CompareAndSwapXxx, 因为这是一个原子性的指令,合理的运用即可做到无锁化并发安全的结构。
atomic包的CompareAndSwapXxx其实就是一个CAS的理念,用乐观锁(逻辑锁)来做数据处理。
unsafa包中的指针的作用:零拷贝string和byte的转换 零拷贝(zero-copy),传统较多的说法就是无需经过用户态到内核态到数据copy,即可做到想做的事情。 通俗一点就是不经过copy就能转换数据。
1 2 3 4 5 6 7 8 9 10 type StringHeader struct { Data uintptr Len int } type SliceHeader struct { Data uintptr Len int Cap int }
这是String和slice的底层数据结构,他们基本是一致的,区别其实就是在于一个有Cap,一个是固定的Len。
只需要共享底层 Data 和 Len 就可以实现 zero-copy。
1 2 3 4 5 6 7 func string2bytes (s string ) []byte return *(*[]byte )(unsafe.Pointer(&s)) } func bytes2string (b []byte ) string return *(*string )(unsafe.Pointer(&b)) }
context控制上下文也讲解一下 我们这里用到了大量协程,他们之间有一些或许是有上下文关系的,因此,我们这里就需要用到context来对协程进行一个上下文的管理,做到协助的作用。
特别是我们在退出程序的时候,我们想要某一些异步任务优雅,可靠,安全的退出程序,那么我们就需要用到context来控制每个后台运行的程序。
我们这里用到比较多的其实就是 context.WithCancel(ctx), 我们需要管理每个协程的退出需要做的事情,例如:我需要msource在退出的时候,保存一下当前在内存中最新的数据到rocksdb中,那么这个时候context的作用就十分有效了。
pprof的查看 要利用pprof粗略查看性能,及时它不能准确的反馈出所有的问题,起码它能帮助我们在前面的大问题上更容易发现问题。
sync.Pool如何做到优化
分别是用到了无锁化结构 以及程序GC的行为的优化