前言 在公司落地一套flink,总结到目前为止做了的事情。
开发环境的部署 我们默认场景下,flink使用hive-catalog,所以hive安装在这里。
Hive使用mysql作为外部数据存储,所以这里使用mysql
对于flink的开发,如果我想要一整套的本地的docker开发环境。
需要集成如下服务:
hadoop
hive
flink
kafka
mysql
所以做了一个flink-docker-compose
在该项目中,由于不是采用CDH来集成的,都是一个个源码包手动安装的。所以需要下载源码包。
目前的版本为:
flink: 1.12.0_2.11
mysql: 5.6 (8.0-jdbc)
kafka: 2.12_2.11
maven: 3.6.3
jdk: 8/11 (默认jdk8)
本地环境的话,jdk需要自行处理好
hadoop: 3.1.1
hive: 3.1.0
一键下载源码包 为了方便方便大家下载,对应的镜像链接,也都集成在了download.sh中,如果需要利用迅雷等p2p加速下载软件,可以通过从中提取出来 url 进行下载。
可设置的.env 利用docker-compose对 .env的支持,可以在当中设置build image的一些环境变量和参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # Hadoop HADOOP_VERSION=3.1.1 # Hive HIVE_VERSION=3.1.0 # Scala SCALA_VERSION=2.11 # Flink FLINK_VERSION=1.12.0 # Kafka KAFKA_VERSION=2.4.0 # Zookeeper ZOOKEEPER_VERSION=3.5.6 # Mysql MYSQL_VERSION=5.6 MYSQL_DATABASE=default MYSQL_PORT=3306 MYSQL_ROOT_PASSWORD=lnhzjm/B4qrSc MYSQL_ENTRYPOINT_INITDB=./deploy/mysql/docker-entrypoint-initdb.d MYSQL_TIMEZONE=UTC
kafka的网络 我们知道kafka的网络协议是支持多端口的,由于我们有时候flink是在本地,有时候是在容器中,所以我们希望我们的kafka集群,支持容器内的网络,也支持和我们物理机的网络。
这个时候,我们需要设置kafka的2套端口协议。所以你可以看到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 kafka1: build: context: ./deploy/kafka args: scala_version: ${SCALA_VERSION} kafka_version: ${KAFKA_VERSION} container_name: flink-kafka1 ports: - '19092:19092' environment: KAFKA_PORT: 19092 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://:9092,EXTERNAL_PLAINTEXT://kafka1:19092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,EXTERNAL_PLAINTEXT:PLAINTEXT KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL_PLAINTEXT://:19092 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_DEFAULT_REPLICATION_FACTOR: 3 networks: flink-networks: ipv4_address: 192.168 .6 .211 extra_hosts: - 'zookeeper:192.168.6.215' - 'kafka1:192.168.6.211' - 'kafka2:192.168.6.212' - 'kafka3:192.168.6.213' - 'kafka4:192.168.6.214' depends_on: - zookeeper
看到这里的
1 2 3 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://:9092,EXTERNAL_PLAINTEXT://kafka1:19092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,EXTERNAL_PLAINTEXT:PLAINTEXT KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL_PLAINTEXT://:19092
这个就是决定我们的2套协议的关键所在,分别是对9092(容器内)和19092(和物理机)端口的支持。
但是设置完了这个,由于一般kafka-client会从可本机的可访问的dns服务器上寻找host映射,在连接的时候必备的流程。
在本地连接的时候,会通过kafka1/kafka2等hostname返回到client,client需要在本机找到所有的ip映射,所以我们需要设置一下etc/hosts
1 echo "127.0.0.1 kafka1 kafka2 kafka3 kafka4" >> /etc/hosts
目前为止,我们所需要的环境变量已经处理完了。
基于datastream-api的flink开发 我们知道flink提供了3种API,分别是datastream-api,table-api,sql-api
datastream,也是flink的最原始的api,和flink集成一体,通过datastream-api,我们可以实现各种灵活的数据流处理。
按照我们以往对流计算数据的处理,在游戏公司中,一个游戏项目部署一个流计算的任务即为合理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 . ├── README.md ├── pom.xml └── src └── main ├── java │ ├── deps │ │ ├── oaYdSdk │ │ │ ├── Youdu.java │ │ │ └── test │ │ │ └── YouduTest.java │ │ └── util │ │ ├── ParameterToolEnvironmentUtils.java │ │ └── Util.java │ └── org │ └── cp │ └── flink │ ├── Bootstrap.java │ ├── async │ │ └── AsyncOaYdHttpClient.java │ ├── events │ │ ├── CommonEvent.java │ │ ├── CommonEventHeader.java │ │ ├── app_error │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ ├── log_ban │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ ├── log_client_loss │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ ├── log_consume_gold │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ ├── log_fcm_error │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ ├── log_index_record │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ ├── log_index_record_data │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ ├── log_role_create │ │ │ ├── Event.java │ │ │ ├── EventHeader.java │ │ │ └── EventLog.java │ │ └── t_log_market │ │ ├── Event.java │ │ ├── EventHeader.java │ │ └── EventLog.java │ ├── jobs │ │ ├── alarm │ │ │ ├── ErrorReport_10008.java │ │ │ ├── Job_10002.java │ │ │ ├── Job_10008.java │ │ │ ├── Job_19.java │ │ │ ├── README.md │ │ │ └── handler │ │ │ ├── AbstractHandler.java │ │ │ ├── errorReport_10008 │ │ │ │ ├── Logic.java │ │ │ │ ├── Logic_10012.java │ │ │ │ ├── Logic_19.java │ │ │ │ └── Logic_20.java │ │ │ ├── job_10002 │ │ │ │ ├── LogIndexRecordDataHandler.java │ │ │ │ ├── LogIndexRecordHandler.java │ │ │ │ └── model │ │ │ │ ├── log_index_record │ │ │ │ │ └── StatisticsMcfx2Model.java │ │ │ │ └── log_index_record_data │ │ │ │ └── StatisticsMcfx1Model.java │ │ │ ├── job_10008 │ │ │ │ ├── AppErrorHandler.java │ │ │ │ ├── LogFcmErrorHandler.java │ │ │ │ └── model │ │ │ │ ├── app_error │ │ │ │ │ └── StatisticsAppErrorModel.java │ │ │ │ └── log_fcm_error │ │ │ │ └── StatisticsFcmErrorModel.java │ │ │ └── job_19 │ │ │ ├── LogBanHandler.java │ │ │ ├── LogClientLossHandler.java │ │ │ ├── LogConsumeGoldHandler.java │ │ │ ├── LogRoleCreateHandler.java │ │ │ ├── TLogMarketHandler.java │ │ │ └── model │ │ │ ├── log_ban │ │ │ │ └── StatisticsModel.java │ │ │ ├── log_client_loss │ │ │ │ └── IpMonitorModel.java │ │ │ ├── log_consume_gold │ │ │ │ ├── StatisticsBindGoldModel.java │ │ │ │ └── StatisticsUnBindGoldModel.java │ │ │ ├── log_role_create │ │ │ │ └── SingleServerRoleCreateModel.java │ │ │ └── t_log_market │ │ │ ├── MarketTransactionLogByBuyerModel.java │ │ │ └── MarketTransactionLogBySellerModel.java │ │ └── stream │ │ └── README.md │ ├── mock │ │ ├── MockAppError.java │ │ ├── MockLogFcmError.java │ │ └── README.md │ ├── serializer │ │ ├── AbstractSerializer.java │ │ └── log_role_create │ │ └── LogRoleCreateDeSerializer.java │ └── sinks │ ├── AsyncOaYdSdkHttpSink.java │ ├── MysqlItem.java │ └── MysqlSink.java └── resources ├── application-dev.properties ├── application-local.properties ├── application-pro.properties ├── application.properties ├── jobs │ ├── org.cp.flink.jobs.alarm.ErrorReport_10008 │ │ ├── application-dev.properties │ │ ├── application-local.properties │ │ ├── application-pro.properties │ │ └── application.properties │ ├── org.cp.flink.jobs.alarm.Job_10002 │ │ ├── application-dev.properties │ │ ├── application-local.properties │ │ ├── application-pro.properties │ │ └── application.properties │ ├── org.cp.flink.jobs.alarm.Job_10008 │ │ ├── application-dev.properties │ │ ├── application-local.properties │ │ ├── application-pro.properties │ │ └── application.properties │ └── org.cp.flink.jobs.alarm.Job_19 │ ├── application-dev.properties │ ├── application-local.properties │ ├── application-pro.properties │ └── application.properties └── log4j2.properties
这是我们早期的一个代码层级结构,所有的流计算任务基于一个flink项目下,resources下的配置根据当前需要提交的项目和环境来进行区分加载具体的配置,可以做到支持多环境,多项目下配置灵活配置。
我们看到 org.cp.flink目下,就是我们的所有flink代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 ➜ flinkjob git:(master) ✗ tree -d src/main/java/org src/main/java/org └── cp └── flink ├── async ├── events │ ├── app_error │ ├── log_ban │ ├── log_client_loss │ ├── log_consume_gold │ ├── log_fcm_error │ ├── log_index_record │ ├── log_index_record_data │ ├── log_role_create │ └── t_log_market ├── jobs │ ├── alarm │ │ └── handler │ │ ├── job_10002 │ │ │ └── model │ │ │ ├── log_index_record │ │ │ └── log_index_record_data │ │ ├── job_10008 │ │ │ └── model │ │ │ ├── app_error │ │ │ └── log_fcm_error │ │ └── job_19 │ │ └── model │ │ ├── log_ban │ │ ├── log_client_loss │ │ ├── log_consume_gold │ │ ├── log_role_create │ │ └── t_log_market │ └── stream ├── mock ├── serializer │ └── log_role_create └── sinks
我们先看到,jobs目录下的,分为了2种类型,我们平时用的流计算任务可以分为2种,一种是常规的告警属性,另一种是产品属性(类似BI系统需要的实时数据)。
我们看到alarm/handler/job_xxx就是我们具体的项目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 src/main/java/org/cp/flink/jobs/alarm/ ├── Job_10002.java ├── Job_10008.java ├── Job_19.java ├── README.md └── handler ├── AbstractHandler.java ├── errorReport_10008 │ ├── Logic.java │ ├── Logic_10012.java │ ├── Logic_19.java │ └── Logic_20.java ├── job_10002 │ ├── LogIndexRecordDataHandler.java │ ├── LogIndexRecordHandler.java │ └── model │ ├── log_index_record │ │ └── StatisticsMcfx2Model.java │ └── log_index_record_data │ └── StatisticsMcfx1Model.java ├── job_10008 │ ├── AppErrorHandler.java │ ├── LogFcmErrorHandler.java │ └── model │ ├── app_error │ │ └── StatisticsAppErrorModel.java │ └── log_fcm_error │ └── StatisticsFcmErrorModel.java └── job_19 ├── LogBanHandler.java ├── LogClientLossHandler.java ├── LogConsumeGoldHandler.java ├── LogRoleCreateHandler.java ├── TLogMarketHandler.java └── model ├── log_ban │ └── StatisticsModel.java ├── log_client_loss │ └── IpMonitorModel.java ├── log_consume_gold │ ├── StatisticsBindGoldModel.java │ └── StatisticsUnBindGoldModel.java ├── log_role_create │ └── SingleServerRoleCreateModel.java └── t_log_market ├── MarketTransactionLogByBuyerModel.java └── MarketTransactionLogBySellerModel.java
对于各个项目的错误告警监控,这里分为了多个job。
Job_10002.java
Job_10008.java
Job_19.java
我们从入口开始看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 package org.cp.flink.jobs.alarm;import com.alibaba.fastjson.JSONObject;import deps.util.Util;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.ProcessFunction;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import org.apache.flink.util.Collector;import org.apache.flink.util.OutputTag;import org.cp.flink.Bootstrap;import org.cp.flink.jobs.alarm.handler.job_10008.AppErrorHandler;import org.cp.flink.jobs.alarm.handler.job_10008.LogFcmErrorHandler;import org.cp.flink.events.CommonEvent;import org.cp.flink.events.app_error.Event;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.Arrays;import java.util.Properties;public class Job_10008 extends Bootstrap private static final Logger logger = LoggerFactory.getLogger(Job_10008.class ) ; public static void main (String[] args) throws Exception final StreamExecutionEnvironment env = getStreamExecutionEnvironment(args, Job_10008.class ) ; env.enableCheckpointing(5000 ); ParameterTool parameterTool = (ParameterTool) env.getConfig().getGlobalJobParameters(); Properties props = new Properties(); props.setProperty("bootstrap.servers" , parameterTool.get("kafka.source.bootstrap.servers" )); props.setProperty("group.id" , parameterTool.get("kafka.source.group" )); props.put("enable.auto.commit" , parameterTool.get("kafka.source.enable.auto.commit" )); props.put("auto.commit.interval.ms" , parameterTool.get("kafka.source.auto.commit.interval.ms" )); props.put("session.timeout.ms" , parameterTool.get("kafka.source.session.timeout.ms" )); props.put("key.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer" ); props.put("value.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer" ); env.setParallelism(parameterTool.getInt("kafka.source.parallelism" , 1 )); DataStream<String> stream = env .addSource(new FlinkKafkaConsumer<>(Arrays.asList(parameterTool.get("kafka.source.topic" ).split("," )), new SimpleStringSchema(), props)); env.setParallelism(parameterTool.getInt("app.parallelism" , 1 )); SingleOutputStreamOperator<CommonEvent> s0 = stream.filter((String json) -> { try { JSONObject.parseObject(json, CommonEvent.class ) ; return true ; } catch (Exception e) { e.printStackTrace(); logger.error(json); } return false ; }).map( (String json) -> JSONObject.parseObject(json, CommonEvent.class ).setOriginJson (json ) ).returns (CommonEvent .class ) ; final OutputTag<CommonEvent> outputTagAppError = new OutputTag<CommonEvent>(AppErrorHandler.class .getName ()) { }; final OutputTag<CommonEvent> outputTagLogFcmError = new OutputTag<CommonEvent>(LogFcmErrorHandler.class .getName ()) { }; SingleOutputStreamOperator<CommonEvent> s1 = s0.process(new ProcessFunction<CommonEvent, CommonEvent>() { @Override public void processElement (CommonEvent event, Context context, Collector<CommonEvent> collector) switch (event.getHeaders().getLogName()) { case "app_error" : context.output(outputTagAppError, event); break ; case "log_fcm_error" : context.output(outputTagLogFcmError, event); break ; } } }); DataStream<CommonEvent> AppErrorSource = s1.getSideOutput(outputTagAppError); DataStream<CommonEvent> LogFcmErrorSource = s1.getSideOutput(outputTagLogFcmError); DataStream<Event> AppErrorSource_s0 = AppErrorSource.map((CommonEvent event) -> JSONObject.parseObject(event.getOriginJson(), Event.class ) ).returns (Event .class ) ; DataStream<org.cp.flink.events.log_fcm_error.Event> LogFcmErrorSource_s0 = LogFcmErrorSource.map((CommonEvent event) -> JSONObject.parseObject(event.getOriginJson(), org.cp.flink.events.log_fcm_error.Event.class ) ).returns (org .cp .flink .events .log_fcm_error .Event .class ) ; AppErrorHandler.build().handle(AppErrorSource_s0); LogFcmErrorHandler.build().handle(LogFcmErrorSource_s0); env.execute(Util.getCurrentJobName(((ParameterTool) env.getConfig().getGlobalJobParameters()))); } }
由于我们一个topic只能够可能存在多种数据,所以这里利用了旁路由进行了分流。把数据流分发到不同的子流中,我们再把子流传递不同的Handler进行处理。
这里例如: AppErrorHandler。我们以此为例子进行说明。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package org.cp.flink.jobs.alarm.handler.job_10008;import lombok.NoArgsConstructor;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.functions.ProcessFunction;import org.apache.flink.util.Collector;import org.apache.flink.util.OutputTag;import org.cp.flink.jobs.alarm.handler.AbstractHandler;import org.cp.flink.jobs.alarm.handler.job_10008.model.app_error.StatisticsAppErrorModel;import org.cp.flink.events.app_error.Event;@NoArgsConstructor public class AppErrorHandler extends AbstractHandler <Event > private static AppErrorHandler instance; public static AppErrorHandler build () if (instance == null ) { instance = new AppErrorHandler(); } return instance; } @Override public void handle (DataStream<Event> s0) ParameterTool parameterTool = this .getParameterTool(s0); final OutputTag<Event> outputTagStatisticsAppError = new OutputTag<Event>(StatisticsAppErrorModel.class .getName ()) { }; SingleOutputStreamOperator<Event> s1 = s0.process(new ProcessFunction<Event, Event>() { @Override public void processElement (Event event, Context context, Collector<Event> collector) context.output(outputTagStatisticsAppError, event); } }); DataStream<Event> sideOutputStreamAppError = s1.getSideOutput(outputTagStatisticsAppError); StatisticsAppErrorModel.build().handle(sideOutputStreamAppError); if (parameterTool.getBoolean("app.handler.print.console" , false )) { s0.print(AppErrorHandler.class .getName ()) ; } } }
由于,我们希望到一条数据从kafka被pull下来到时候,可以用于多个不同的流计算模型model,所以我们在这里需要copy到多个旁路输出,但是这里我们只有一个stream-model,所以我们就只用一个来处理即可,从旁路输出拿到datastream之后,在对应的模型中进行核心逻辑处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 package org.cp.flink.jobs.alarm.handler.job_10008.model.app_error;import deps.util.Util;import lombok.NoArgsConstructor;import org.apache.flink.api.java.functions.KeySelector;import org.apache.flink.api.java.tuple.Tuple3;import org.apache.flink.api.java.tuple.Tuple5;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.datastream.WindowedStream;import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;import org.apache.flink.streaming.api.functions.windowing.WindowFunction;import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import org.apache.flink.streaming.runtime.operators.util.AssignerWithPeriodicWatermarksAdapter;import org.apache.flink.util.Collector;import org.cp.flink.jobs.alarm.handler.AbstractHandler;import org.cp.flink.events.app_error.Event;import org.cp.flink.jobs.alarm.handler.job_19.model.log_ban.StatisticsModel;import org.cp.flink.sinks.MysqlItem;import org.cp.flink.sinks.MysqlSink;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.time.Duration;import java.util.HashMap;import java.util.concurrent.TimeUnit;@NoArgsConstructor public class StatisticsAppErrorModel extends AbstractHandler <Event > private static final String DEFAULT_SINK_DATABASE = "db_app_log_alarm" ; private static final String DEFAULT_SINK_TABLE = "t_log_app_error_alarm_164" ; private static final Logger logger = LoggerFactory.getLogger(StatisticsAppErrorModel.class ) ; private static StatisticsAppErrorModel instance; public static StatisticsAppErrorModel build () if (instance == null ) { instance = new StatisticsAppErrorModel(); } return instance; } @Override public void handle (DataStream<Event> s0) s0.getExecutionConfig().setAutoWatermarkInterval(5000L ); logger.debug("getAutoWatermarkInterval: {}" , s0.getExecutionConfig().getAutoWatermarkInterval()); ParameterTool parameterTool = this .getParameterTool(s0); SingleOutputStreamOperator<Event> s1 = s0.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksAdapter.Strategy<>( new BoundedOutOfOrdernessTimestampExtractor<Event>(Time.of(1 , TimeUnit.SECONDS)) { @Override public long extractTimestamp (Event event) Long ts = event.getLogs().getMtime() * 1000L ; logger.debug( "thread-id: {}, eventTime: [{}|{}], watermark: [{}|{}]" , Thread.currentThread().getId(), ts, sdf.format(ts), this .getCurrentWatermark().getTimestamp(), sdf.format(this .getCurrentWatermark().getTimestamp()) ); return ts; } } ) .withIdleness(Duration.ofMinutes(1L )) ); WindowedStream<Event, Tuple5<Integer, String, String, Integer, String>, TimeWindow> s2 = s1.keyBy(new KeySelector<Event, Tuple5<Integer, String, String, Integer, String>>() { @Override public Tuple5<Integer, String, String, Integer, String> getKey (Event event) return Tuple5.of( event.getLogs().getRelatedAppId(), event.getLogs().getChildApp(), event.getLogs().getSummary(), event.getLogs().getLevel(), event.getLogs().getIp() ); } }) .window(TumblingEventTimeWindows.of(Time.minutes(1L ))); SingleOutputStreamOperator<Tuple3<Tuple5<Integer, String, String, Integer, String>, Event, Integer>> s3 = s2.apply(new WindowFunction<Event, Tuple3<Tuple5<Integer, String, String, Integer, String>, Event, Integer>, Tuple5<Integer, String, String, Integer, String>, TimeWindow>() { public void apply (Tuple5<Integer, String, String, Integer, String> key, TimeWindow timeWindow, Iterable<Event> iterable, Collector<Tuple3<Tuple5<Integer, String, String, Integer, String>, Event, Integer>> collector) throws Exception int sum = 0 ; for (Event event : iterable) { sum++; } logger.debug("聚合窗口key: {}, 窗口中的数量:{}, 此时的窗口范围是[{},{})" , key, sum, sdf.format(timeWindow.getStart()), sdf.format(timeWindow.getEnd())); collector.collect(Tuple3.of(key, iterable.iterator().next(), sum)); } }); String sinkDatabase = parameterTool.get(StatisticsModel.class.getName() + ".sink_database", DEFAULT_SINK_DATABASE); String sinkTable = parameterTool.get(StatisticsModel.class.getName() + ".sink_table", DEFAULT_SINK_TABLE); SingleOutputStreamOperator<MysqlItem> s4 = s3.map(e -> { HashMap<String, Object> kv = new HashMap<>(); kv.put("related_app_id" , e.f1.getLogs().getRelatedAppId()); kv.put("child_app" , e.f1.getLogs().getChildApp()); kv.put("summary" , e.f1.getLogs().getSummary()); kv.put("level" , e.f1.getLogs().getLevel()); kv.put("ip" , e.f1.getLogs().getIp()); kv.put("mtime" , e.f1.getLogs().getMtime()); kv.put("mdate" , Util.timeStamp2Date(Integer.toString(e.f1.getLogs().getMtime()), "yyyy-MM-dd" )); kv.put("cnt" , e.f2); return MysqlItem.builder() .database(sinkDatabase) .table(sinkTable) .kv(kv) .build(); } ).returns(MysqlItem.class ) ; s4.addSink(new MysqlSink(parameterTool)) .setParallelism(parameterTool.getInt("mysql.sink.parallelism" , 1 )) .name("MysqlSink" ); if (parameterTool.getBoolean("app.handler.print.console" , false )) { s0.print(StatisticsAppErrorModel.class .getName ()) ; } } }
从上面的整体中,我们这里先看到设置watermark的逻辑,这个watermark决定了我们的flink的数据的有序性,是一个比较重要的处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 s0.getExecutionConfig().setAutoWatermarkInterval(5000L ); logger.debug("getAutoWatermarkInterval: {}" , s0.getExecutionConfig().getAutoWatermarkInterval()); ParameterTool parameterTool = this .getParameterTool(s0); SingleOutputStreamOperator<Event> s1 = s0.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksAdapter.Strategy<>( new BoundedOutOfOrdernessTimestampExtractor<Event>(Time.of(1 , TimeUnit.SECONDS)) { @Override public long extractTimestamp (Event event) Long ts = event.getLogs().getMtime() * 1000L ; logger.debug( "thread-id: {}, eventTime: [{}|{}], watermark: [{}|{}]" , Thread.currentThread().getId(), ts, sdf.format(ts), this .getCurrentWatermark().getTimestamp(), sdf.format(this .getCurrentWatermark().getTimestamp()) ); return ts; } } ) .withIdleness(Duration.ofMinutes(1L )) );
我们这里通过AssignerWithPeriodicWatermarksAdapter设置一个watermark生成的策略。
当数据到来的时候,允许1秒延迟的情况下,解析数据的事件时间(event-time)作为我们的watermark,这里需要注意的是,这里从event-time提取的时间的单位需要是毫秒级别。
再通过.withIdleness,进行当某个窗口下idle了,那么也会刷新watermark。这个知识点,在kafka中是一个很重要的逻辑,由于flink在kafka的topic在多partition下,在partition的数据watermark对齐的情况,才会进行,所以为了防止,由于防止kafka的partition的数据倾斜对我们造成业务逻辑一直无法更新watermark的问题。这个十分必要。
1 2 3 4 5 6 7 8 9 10 11 12 13 WindowedStream<Event, Tuple5<Integer, String, String, Integer, String>, TimeWindow> s2 = s1.keyBy(new KeySelector<Event, Tuple5<Integer, String, String, Integer, String>>() { @Override public Tuple5<Integer, String, String, Integer, String> getKey (Event event) return Tuple5.of( event.getLogs().getRelatedAppId(), event.getLogs().getChildApp(), event.getLogs().getSummary(), event.getLogs().getLevel(), event.getLogs().getIp() ); } }) .window(TumblingEventTimeWindows.of(Time.minutes(1L )));
对于windowstream,主要是定义窗口的时间大小, 窗口数据的唯一主键。
在这里,由于我的需求是每1分钟统计一次,所以这里可以看到我的窗口是基于EventTime(事件时间)的窗口,并且大小范围为1分钟。而数据的唯一主键则是通过getKet(Event event)方法来处理。通过flink内置的便捷的Tuple5这个类来处理的原因是因为我这里有5个元素组成的key。
1 2 3 4 5 6 7 8 9 10 11 SingleOutputStreamOperator<Tuple3<Tuple5<Integer, String, String, Integer, String>, Event, Integer>> s3 = s2.apply(new WindowFunction<Event, Tuple3<Tuple5<Integer, String, String, Integer, String>, Event, Integer>, Tuple5<Integer, String, String, Integer, String>, TimeWindow>() { public void apply (Tuple5<Integer, String, String, Integer, String> key, TimeWindow timeWindow, Iterable<Event> iterable, Collector<Tuple3<Tuple5<Integer, String, String, Integer, String>, Event, Integer>> collector) throws Exception int sum = 0 ; for (Event event : iterable) { sum++; } logger.debug("聚合窗口key: {}, 窗口中的数量:{}, 此时的窗口范围是[{},{})" , key, sum, sdf.format(timeWindow.getStart()), sdf.format(timeWindow.getEnd())); collector.collect(Tuple3.of(key, iterable.iterator().next(), sum)); } });
接下来就是聚合(统计)的逻辑了,当window-trigger-condition满足条件之后,就会把当前窗口内的所有数据推到下一个算子,在这个算子的apply()中,我们可以看到我们只是简单的做了一个数据统计,也就是sum++,经过这一操作之后,经过collector对进行进行收集,准备用于下一个算子中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SingleOutputStreamOperator<MysqlItem> s4 = s3.map(e -> { HashMap<String, Object> kv = new HashMap<>(); kv.put("related_app_id" , e.f1.getLogs().getRelatedAppId()); kv.put("child_app" , e.f1.getLogs().getChildApp()); kv.put("summary" , e.f1.getLogs().getSummary()); kv.put("level" , e.f1.getLogs().getLevel()); kv.put("ip" , e.f1.getLogs().getIp()); kv.put("mtime" , e.f1.getLogs().getMtime()); kv.put("mdate" , Util.timeStamp2Date(Integer.toString(e.f1.getLogs().getMtime()), "yyyy-MM-dd" )); kv.put("cnt" , e.f2); return MysqlItem.builder() .database(sinkDatabase) .table(sinkTable) .kv(kv) .build(); } ).returns(MysqlItem.class ) ; s4.addSink(new MysqlSink(parameterTool)) .setParallelism(parameterTool.getInt("mysql.sink.parallelism" , 1 )) .name("MysqlSink" );
在这个前面到算子中,我们拿到了一些我们所期待到数据了,接下来就是把数据转换成为我们需要入库的一个结构。通过MysqlItem对象,我们把所有的结构化的对象通过MysqlSink方法进行发送给mysql。mysqlsink是我们自己封的一个sinker,其中的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 package org.cp.flink.sinks;import lombok.Setter;import lombok.experimental.Accessors;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.configuration.Configuration;import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.nio.charset.StandardCharsets;import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;import java.sql.SQLException;@Setter @Accessors (chain = true )public class MysqlSink extends RichSinkFunction <MysqlItem > private static final Logger logger = LoggerFactory.getLogger(MysqlSink.class ) ; ParameterTool parameterTool; private Connection connection; public MysqlSink (ParameterTool parameterTool) this .parameterTool = parameterTool; } @Override public void open (Configuration parameters) throws Exception super .open(parameters); if (connection == null ) { connection = this .getConnection(); } } @Override public void close () throws Exception super .close(); if (connection != null ) { connection.close(); } } public void invoke (MysqlItem item, Context context) logger.debug("mysql-item: {}" , item); MysqlItem.Sql sqlInfo = item.toInsertIgnoreSql(); String sql = sqlInfo.getPreSql(); try { PreparedStatement ps = this .connection.prepareStatement(sql); for (int i = 1 ; i <= sqlInfo.getValues().size(); i++) { ps.setObject(i, sqlInfo.getValues().get(i-1 )); } logger.debug(ps.toString()); ps.execute(); } catch (Exception e) { e.printStackTrace(); logger.error(e.getMessage()); } } private Connection getConnection () throws ClassNotFoundException, SQLException Class.forName("com.mysql.cj.jdbc.Driver" ); return DriverManager.getConnection( String.format( "jdbc:mysql://%s:%s/?useUnicode=true&characterEncoding=%s&useSSL=false&autoReconnect=true" , this .parameterTool.get("mysql.sink.host" ), this .parameterTool.get("mysql.sink.port" ), this .parameterTool.get("mysql.sink.characterEncoding" , StandardCharsets.UTF_8.toString()) ), this .parameterTool.get("mysql.sink.user" ), this .parameterTool.get("mysql.sink.password" ) ); } }
到此,一个基于datastream-api的job,就完成了。
但是由于这是java技术栈,对于不是java技术栈的团队而言,这是一件比较麻烦的事情。就算是java技术栈,也需要去属于了解flink的原理,然后去编写对应的flink代码,这对于不熟悉datastream-api的小伙伴来说,也是一种头痛的事情。
所以对于这个问题,我们考虑使用上层一些的api,也就是table-api和sql-api。
但是由于此类api还是需要熟悉api的细节,所以我们看到了flink提供了一个叫sql-client的东西。但是由于sql-client的不稳定性(某些版本下存在比较严重的bug),且某些需求无法满足我们,为了灵活和可控性,我们最终解决了自行开发flink-sql-client。
基于自研sql-client的flink开发 具体的实现方式在 flink-sql-submit
实现原理其实也不复杂,其实就是通过一个flink项目,封装成为一个类似cmd的命令,然后通过此方式来提交我们的sql或者sql文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 src/main/java/ ├── deps │ └── util │ ├── ParameterToolEnvironmentUtils.java │ ├── SqlCommandParser.java │ └── Util.java └── org └── client └── flink ├── Bootstrap.java ├── SqlSubmit.java ├── cmds │ ├── AbstractCommand.java │ ├── HelpCommand.java │ ├── HiveCatalogCommand.java │ ├── ICommand.java │ ├── JobCommand.java │ └── SqlParserCommand.java ├── enums │ └── PlanType.java ├── internals └── udfs
我们可以看到,整个项目只有少量文件。提供了几个命令:
help 帮助命令
hivecatalog 管理
job 提交任务
sql-parser 调试解析sql
我们以一个sql-file为例子,其他大家可以在github上查看源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 CATALOG_INFO = hive:/opt/hadoopclient/Hive/config/:-; CREATE DATABASE mstream_alarm COMMENT '告警系统流计算' ;USE mstream_alarm;SET 'pipeline.name' = '每1分钟基础服务告警' ;SET 'table.exec.emit.early-fire.enabled' = 'true' ;SET 'table.exec.emit.early-fire.delay' = '10s' ;SET 'mc.local.time.zone' = 'Asia/Shanghai' ;SET 'table.exec.sink.not-null-enforcer' = 'drop' ;SET 'execution.checkpointing.mode' = 'EXACTLY_ONCE' ;SET 'execution.checkpointing.interval' = '2min' ;SET 'execution.checkpointing.timeout' = '1min' ;SET 'execution.checkpointing.prefer-checkpoint-for-recovery' = true ;SET 'execution.checkpointing.externalized-checkpoint-retention' = 'RETAIN_ON_CANCELLATION' ;SET 'mc.state.backend.fs.checkpointdir' = 'hdfs:///flink/checkpoints/{db}/{pipeline.name}' ;SET 'mc.execution.savepoint.dir' = 'hdfs:///flink/savepoints/{db}/{pipeline.name}' ;SET 'restart-strategy' = 'failure-rate' ;SET 'restart-strategy.failure-rate.delay' = '10s' ;SET 'restart-strategy.failure-rate.failure-rate-interval' = '5min' ;SET 'restart-strategy.failure-rate.max-failures-per-interval' = '10' ;CREATE TABLE app_error_To_t_log_app_error_alarm_164 ( headers ROW <`app_id` int ,`log_name` string >, logs ROW <`related_app_id` int , `child_app` varchar (200 ), `summary` string ,`level` int ,`ip` varchar (200 ),`detail` varchar (100 ), `mtime` int >, etime as TO_TIMESTAMP(FROM_UNIXTIME(logs.`mtime` )), WATERMARK for etime AS etime ) WITH ( 'connector' = 'kafka' , 'topic' = 'mfeilog_dsp_10008_app_error' , 'properties.bootstrap.servers' = '127.0.0.1:9092' , 'properties.group.id' = 'app_error_to_t_log_app_error_alarm_164' , 'format' = 'json' , 'scan.startup.mode' = 'latest-offset' , 'json.fail-on-missing-field' = 'false' , 'json.ignore-parse-errors' = 'false' ); CREATE TABLE `t_log_app_error_alarm_164` ( `related_app_id` int , `child_app` varchar (200 ), `summary` string , `level` int , `ip` varchar (200 ) , `cnt` varchar (200 ) COMMENT 'calculate the detail of count()' , `mdate` string , `mtime` int , PRIMARY KEY (`related_app_id` ,`child_app` ,`summary` ,`level` ,`ip` ) NOT ENFORCED ) WITH ( 'connector' = 'jdbc' , 'url' = 'jdbc:mysql://127.0.0.1:60701/db_app_log_alarm?useUnicode=true&characterEncoding=utf8&autoReconnect=true' , 'driver' = 'com.mysql.cj.jdbc.Driver' , 'table-name' = 't_log_app_error_alarm_164' , 'username' = 'flink_mstream_alarm' , 'password' = 'xxxx' ); insert into t_log_app_error_alarm_164 ( select t1.`related_app_id` ,t1.`child_app` ,t1.`summary` ,t1.`level` ,t1.`ip` ,cast (t1.`cnt` as VARCHAR (200 )) as `cnt` ,t1.`mdate` ,cast (t1.`mtime` as INT ) from ( select logs.`related_app_id` as `related_app_id` , logs.`child_app` as `child_app` , logs.`summary` as `summary` , logs.`level` as `level` , logs.`ip` as `ip` , DATE_FORMAT (TUMBLE_START(etime, INTERVAL '1' MINUTE ), 'yyyy-MM-dd' ) as `mdate` , UNIX_TIMESTAMP (DATE_FORMAT (TUMBLE_START(etime, INTERVAL '1' MINUTE ), 'yyyy-MM-dd HH:mm:ss' )) as `mtime` , COUNT (logs.`detail` ) as `cnt` FROM app_error_To_t_log_app_error_alarm_164 GROUP BY logs.`related_app_id` , logs.`child_app` ,logs.`summary` ,logs.`level` ,logs.`ip` ,TUMBLE(etime, INTERVAL '1' MINUTE ) ) t1 );
我们可以看到这个sql-file,支持了一些关键字,这些关键字被开发在client当中了,所以可以被正常解析到。
通过解析到关键字,再调用对应的API,我们就可以设置对应的行为了。
我们可以看到我们从繁杂的datastreamapi中,已经把剥离了出来,通过sql这种DSL的方式,让不同语言技术栈的同事都可以定制自己的job。
并且支持了自定义重启策略,保证每一个算子在异常或者正常的情况下,都可以从正确的数据中进行恢复重启。
这一套sql编写下来,做的事情和我们上面的datastream做的事情是一样的,但是却无需了解太多其中的细节。
UDF的运用 例如我们需要ip转地址字符串,这个时候,我们就需要udf来协助我们完成这件事。
client项目可以内置一些我们所需要的UDF,然后连同job一起生效。
例如:
1 2 3 4 5 6 7 8 [root@127.0,0.1_A ~]# flink run -yid `cat /data/flink-stream/mstream/mstream_xx/yid` /data/flink-stream/flink-sql-submit-1.0-SNAPSHOT.jar job --sql "CATALOG_INFO = hive:/opt/hadoopclient/Hive/config/:-;USE mstream_alarm;SELECT ip2location('219.135.155.76');" Interface ana-group-1byez.dad44e53-24e6-41be-bfd5-a4055f4c6604.com:32263 of application 'application_1641337362340_6699'. Job has been submitted with JobID 824af5a31aba88db6e0137f5e834f26b +----+--------------------------------+ | op | EXPR$0 | +----+--------------------------------+ | +I | 中国,广东,广州 | +----+--------------------------------+
我们可以看到,通过ip2localtion(),我们完成了一个udf,并且可以实现在sql的模式上。用过ip地址转为为了地址。
落地实战 由于资源的有限,我们在flink的架构上,采用的是每个项目对应一个application的方法,每个application通过yarn来分配来分配资源容器,然后再通过yarn-session(非per on job)的方式来管理我们的flink应用。
申请资源应用 1 yarn-session.sh -jm 1024 -tm 1024 -s 16 -nm '告警流计算应用' -yd
client 例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 # help root@41c5967b5948:/www# flink run target/mc-flink-sql-submit-1.0-SNAPSHOT.jar help 帮助命令 Usage of "flink run <.jar> help [options]" Available Commands job 提交job作业 sql-parser 解析sql文件 help 帮助命令 hive-catalog hive-catalog的相关 Global Options: --app.force.remote bool 是否启动远端环境变量: false --app.config.debug bool 是否打印用户参数: false # job root@41c5967b5948:/www# flink run target/mc-flink-sql-submit-1.0-SNAPSHOT.jar job help 提交job Usage of "flink run <.jar> job [options]" --sql string 执行的sql (*) --plan string 选择执行计划器: flink-streaming flink-batch blink-streaming flink-batch Global Options: --app.force.remote bool 是否启动远端环境变量: false --app.config.debug bool 是否打印用户参数: false
flink-stream-sql-mctl 用法 这是一个集成脚本,所以存在约定的规则和部署的架构约束。
这便于我们管理所有的applition和flink种的所有flink-job。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 flink-sql-submit git:(master) ✗ ./flink-stream-sql-mctl.sh flink-stream-sql-mctl.sh [OPTION] <COMMAND> Flink流计算SQL-Client的执行脚本 Command: run [FILE] 运行 stop [FILE] 停止 list [FILE] 列出FILE所在yid下的所有job任务列表 drop_table [FILE] 删除所有表 rebuild_run [FILE] 删除所有表,然后重跑(继承savepoint) Command-Common-Options: -c, --clientpath [LEVEL] flink-sql-submit.jar路径 (Default is '/data/tmp/mc-flink-sql-submit-1.0-SNAPSHOT.jar') -f 是否强制运行,忽略以往savepoint Common-Options: -h, --help Display this help and exit --loglevel [LEVEL] One of: FATAL, ERROR, WARN, INFO, NOTICE, DEBUG, ALL, OFF (Default is 'ERROR') --logfile [FILE] Full PATH to logfile. (Default is '/Users/caiwenhui/logs/flink-stream-sql-mctl.sh.log') -n, --dryrun Non-destructive. Makes no permanent changes. -q, --quiet Quiet (no output) -v, --verbose Output more information. (Items echoed to 'verbose') --force Skip all user interaction. Implied 'Yes' to all actions.
约定规则:
模型所在父目录的至少有一个yid文件(取最近的一个父节点的yid)对应所在的应用id
默认情况下,模型启动的时候会取最近一次savepoint的数据进行恢复,如果不存在,则直接启动
停止所有模型 1 for i in $(find /data/flink-stream/mstream_alarm/ -type f -name "*.sql");do /data/flink-stream/flink-stream-sql-mctl stop $i;done
启动所有模型 1 for i in $(find /data/flink-stream/mstream_alarm/ -type f -name "*.sql");do /data/flink-stream/flink-stream-sql-mctl run $i;done
删除所有表 1 for i in $(find /data/flink-stream/mstream_alarm/ -type f -name "*.sql");do /data/flink-stream/flink-stream-sql-mctl drop_table $i;done
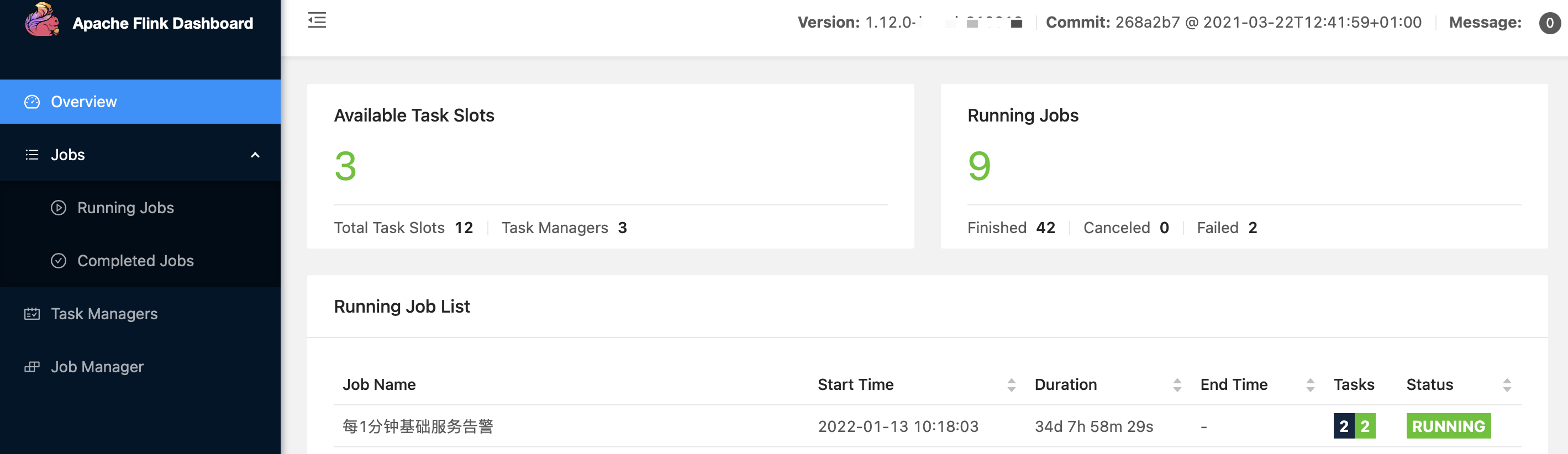
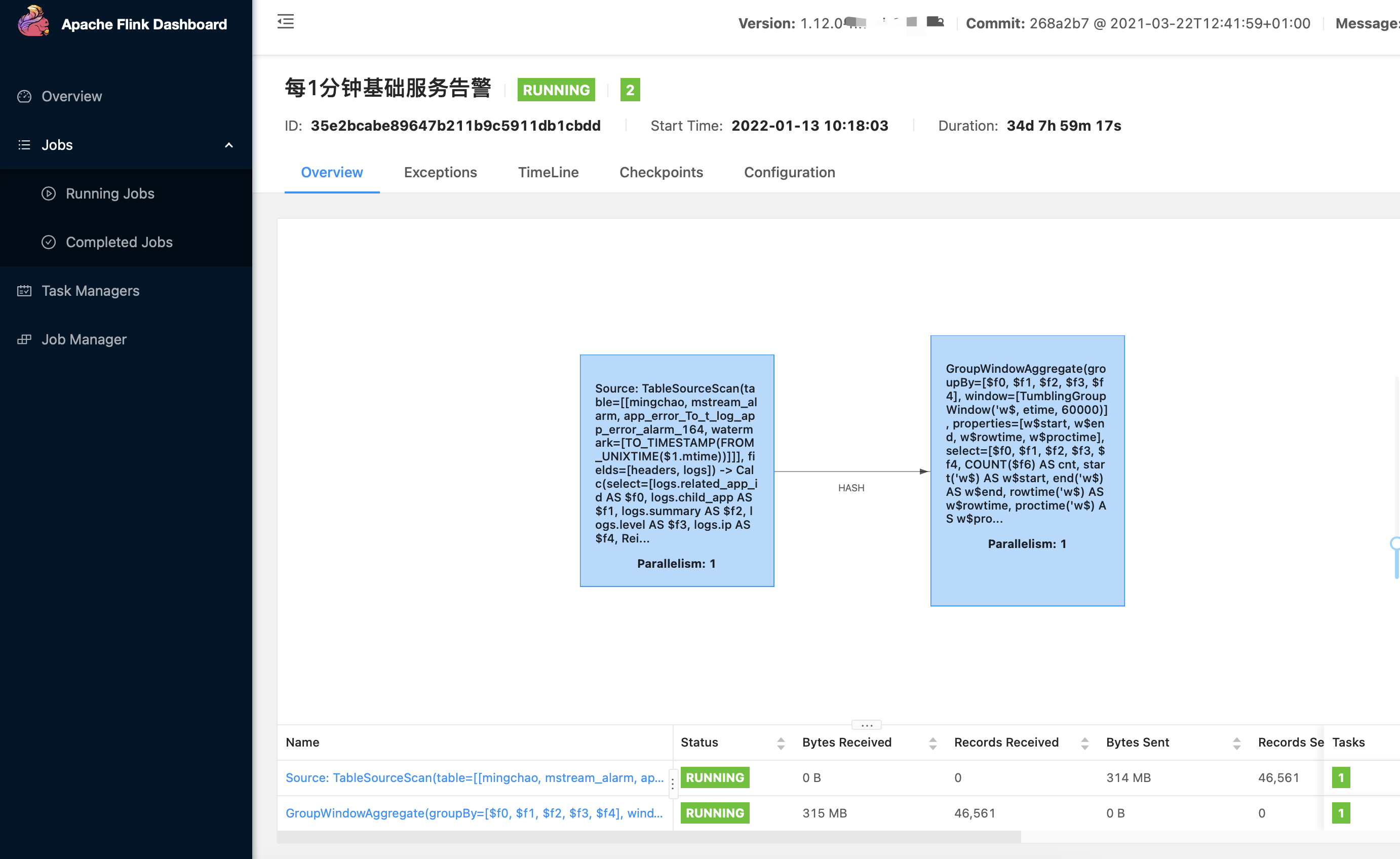
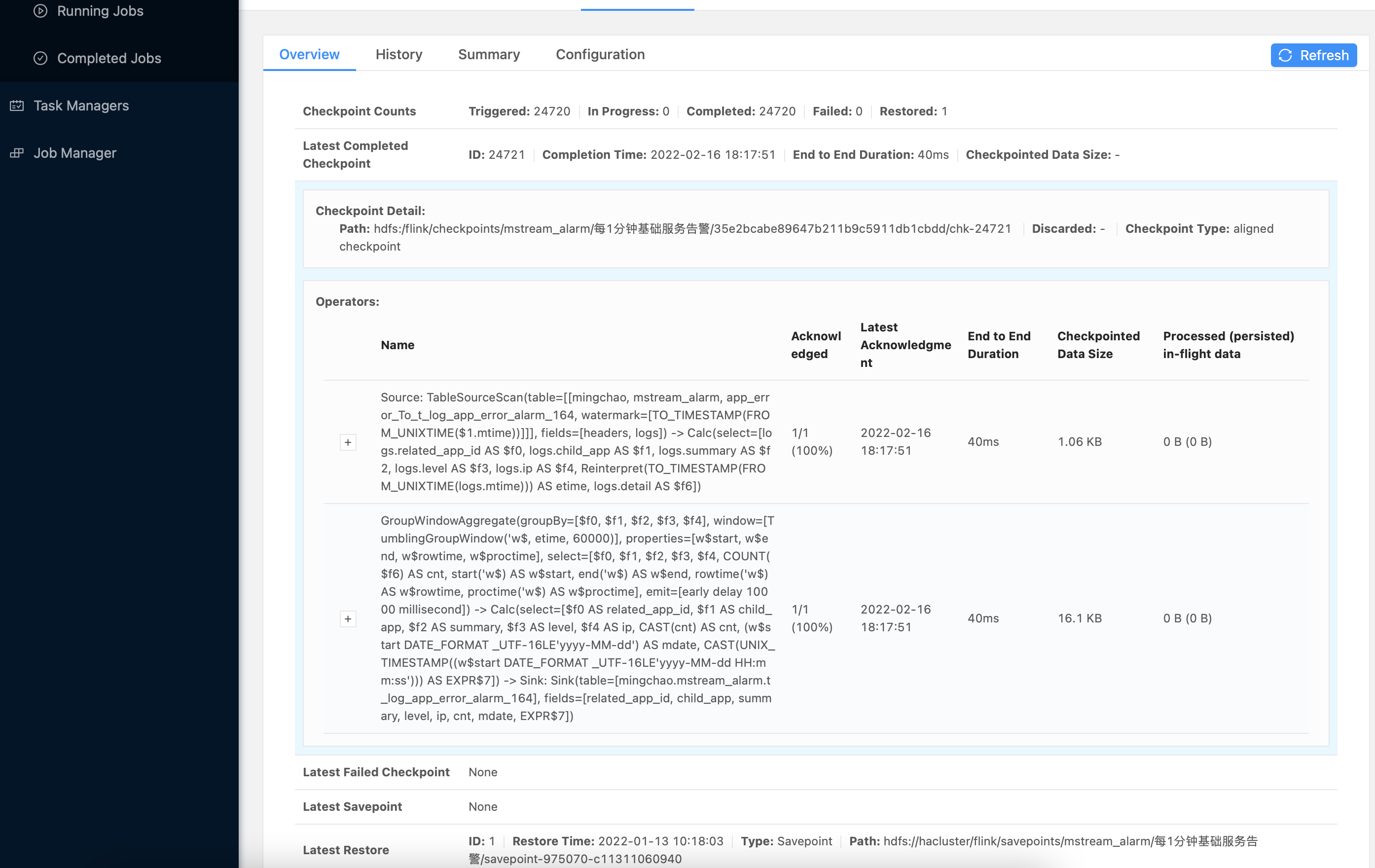
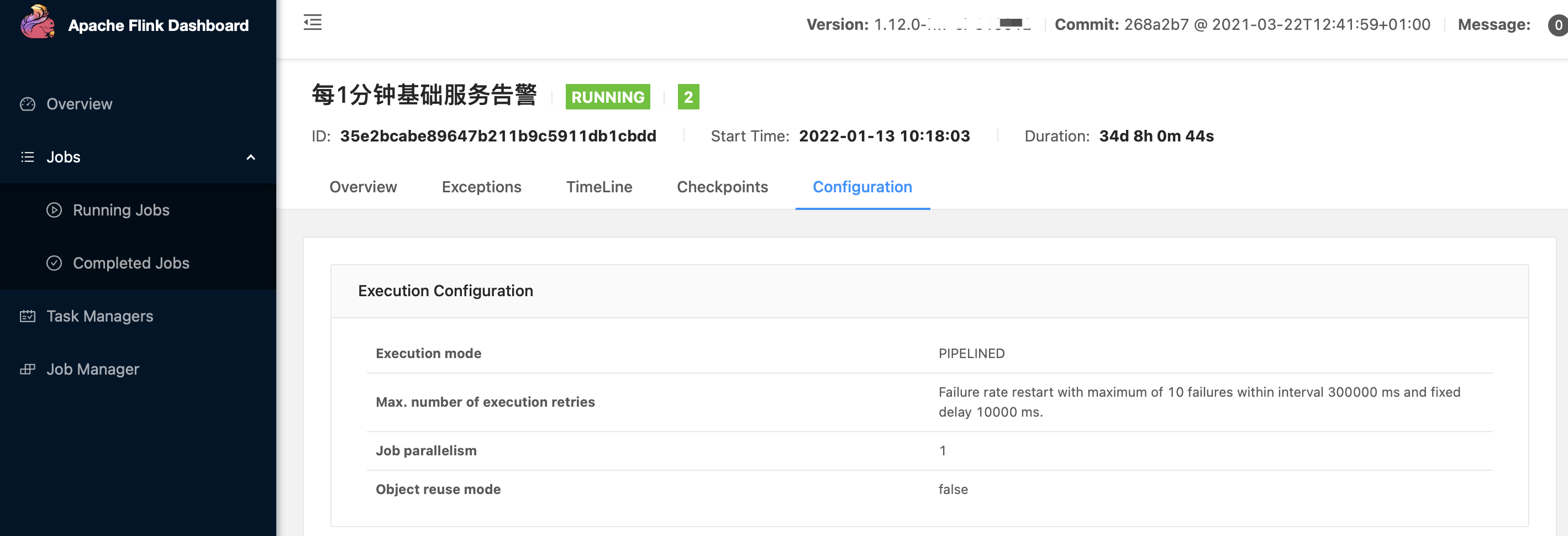
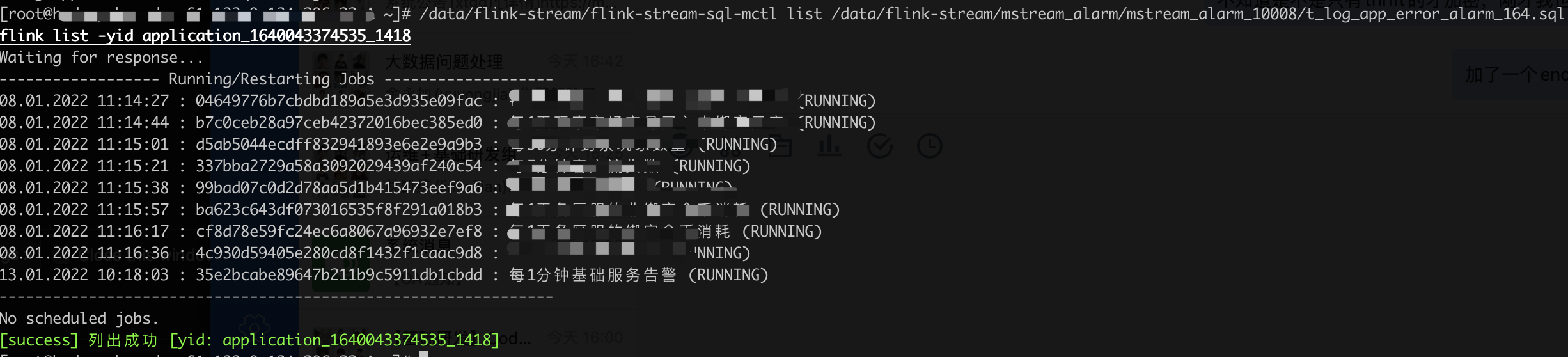
相关的一些落地后截图信息
到此为止,我们的flink相关的流计算应用,从0到1的过程暂时画上一个里程碑。